From data to insights: AI secrets for market research professionals
In an era where data is king, the integration of artificial intelligence (AI) into market research is revolutionizing the way we gather and interpret insights. In his recent webinar "From Data to Insights: AI Secrets for Market Research Professionals", Florian Polak, co-founder of Tucan.ai, provided a deep dive into the practical applications of AI in market research. This blog post offers a detailed summary of the webinar on martforschung.de, spotlighting the benefits AI solutions can bring to the industry.
"We know how crucial the transparency and reliability of the results provided by our AI is."

Interview Marktforschung.de with Florian Polak
Managing Director, Tucan.ai GmbH
Edit Content
Edit Content
AI based summary by Tucan.ai
Einführung und Überblick:
– Florian Polak, Geschäftsführer von Tucan.ai, führte durch das Webinar zur Woche der Marktforschung.
– Tucan.ai ist ein junges Unternehmen aus Berlin, spezialisiert auf die Extraktion relevanter Informationen aus Text-, Audio- und Videodateien für Marktforschungszwecke.
KI-Systeme und Anwendungen:
– Es wurde ein Überblick über KI-Systeme und deren Anwendung in der Marktforschung gegeben, inklusive Tipps und Tricks für den effizienten Einsatz.
– Tucan.ai bietet Produkte an, die es ermöglichen, KI-Technologien zur Effizienzsteigerung und zur Überholung der Konkurrenz einzusetzen.
Probleme und Lösungen bei KI-Systemen:
– Diskussion über gängige Probleme bei der Nutzung von KI-Systemen, insbesondere das Phänomen der “Halluzination” von KI, ungenaue oder oberflächliche Antworten und Datenschutzbedenken.
– Tucan.ai nutzt spezielle Technologien und Ansätze, um präzise und relevante Ergebnisse zu liefern und gleichzeitig Datenschutz und Sicherheit zu gewährleisten.
Anwendungsbereiche und Funktionen:
– Tucan.ai’s Software ermöglicht die Auswertung von Online-Communities, qualitative Kodierung von Interviews oder Gruppenstudien und quantitative Auswertung von Textdaten.
– Die Software unterstützt verschiedene Datenformate und bietet eine hohe Verarbeitungsgeschwindigkeit und Genauigkeit.
Datenschutz und Sicherheit:
– Tucan.ai garantiert, dass Daten ausschließlich in Deutschland verarbeitet werden und bietet verschiedene Kooperationsmodelle an, einschließlich On-Premise-Lösungen.
Preismodelle:
– Tucan.ai bietet flexible Preismodelle an, die auf Projektbasis oder als jährliche Pauschale gestaltet werden können, abhängig von den Bedürfnissen des Kunden.
Fragen und Antworten:
– Im Webinar wurden verschiedene Fragen der Teilnehmer beantwortet, unter anderem zur Verarbeitung von Dialekten, der Möglichkeit, Audiodateien zu testen, und zur Verarbeitung und Analyse von demografischen Daten in Verbindung mit offenen Antworten.
Abschluss:
– Das Webinar endete mit dem Angebot, bei weiteren Fragen Kontakt aufzunehmen und der Ankündigung, dass eine Zusammenfassung des Webinars zur Verfügung gestellt wird.
Edit Content
AI based transcript by Tucan.ai
Florian Polak: 00:00:02,950 –> 00:00:41,380
Schönen guten Tag. Hallo. Florian Polak ist mein Name hier von Tucan.ai. Willkommen bei unserem Webinar zur Woche der Marktforschung von Tucan.ai. Ich glaube, wir können schon anfangen. Ich werde Ihnen ganz kurz nur den Ablauf erklären. Ich werde Ihnen einen Überblick geben zu verschiedenen Themen im Rahmen der CI Forschung. Natürlich. Ähm, wir werden im Anschluss. Ich glaube, ich schätze mal, dass ich so 20 30 Minuten maximal brauchen werde. Wenn werden im Anschluss auch eine Fragerunde machen. Haben Sie in der Zwischenzeit Fragen? Bitte schreiben Sie die in unseren Chat einfach hinein und am Schluss, im Anschluss des Webinars, werde ich natürlich alle Fragen beantworten, die Sie im Chat gestellt haben.
Florian Polak: 00:00:42,400 –> 00:01:21,640
Wunderbar. Dann würde ich ganz kurz anfangen. Vielleicht ganz kurz zu mir. Florian Polak hier. Ich bin einer der Geschäftsführer von Tucan.ai. Mein Job, abgesehen davon Webinare zu halten, ist es mehr oder weniger eigentlich zu übersetzen, was unsere technische Abteilung alles macht. Wir sind ein junges Unternehmen aus Berlin, die mittlerweile seit fünf Jahren am Markt und haben uns darauf fokussiert, gerade im Bereich Marktforschung relevante Informationen aus einer großen Menge von Text oder auch aus Audio oder Videodateien im Prinzip zu extrahieren. Ich werde Ihnen einen kurzen Überblick jetzt mal geben. Wunderbar, wir fangen auch schon an, was werde ich in diesem Webinar alles machen?
Florian Polak: 00:01:22,360 –> 00:01:57,730
Ich werde ein bisschen eingehen auf KI Systeme und Begrifflichkeiten da drin in Ihnen versuchen simpel einen Überblick zu geben. Ohne jetzt zu sehr in die Details hier reinzugehen. Ich werde Ihnen vor allem aber auch ein paar Tipps und Tricks auf den Weg geben, worauf Sie vielleicht beim Arbeiten mit KI auch achten sollten. Und ich werde Ihnen natürlich auch zeigen, was wir grundsätzlich für Produkte anbieten und wie Sie entweder mit uns oder auch das selber im Prinzip aufbauen können, dass Sie KI Technologien bei Ihnen einsetzen und im Prinzip damit natürlich sehr, sehr effizient ihre Konkurrenz im Prinzip abhängen können.
Florian Polak: 00:01:59,660 –> 00:02:29,660
Was ist auf der Agenda? Hier eine kurze Vorstellungsrunde zu uns machen, was wir so machen, was wir grundsätzlich anbieten. Ich werde dann vor allem aber auch einen Fokus darauf legen, was für Probleme mit KI Systemen eigentlich sind, sondern was man da eigentlich ein bisschen achten sollte. Ich werde ein bisschen darauf eingehen, wie so grundsätzlich der Markt aktuell agiert und was gut daran ist und was vielleicht nicht so gut daran ist. Dann gebe ich Ihnen natürlich auch einen Überblick über unsere Software und werde Ihnen auch verraten, im Prinzip, was hinter unserem System steckt, wie wir das Ganze im Prinzip aufgebaut haben.
Florian Polak: 00:02:30,260 –> 00:03:08,210
Um Ihnen einfach nochmal einen Überblick zu geben, warum unser System in diesem Fall sehr gut geeignet ist für die Marktforschung. Dann natürlich zu guter Letzt noch ein kleines Thema über das Thema Datenschutz natürlich. Und Sicherheit ist sehr wichtig, gerade in der Auswertung von Studien und natürlich, was wir grundsätzlich für Preispakete haben, damit Sie den Überblick haben. Zu guter Letzt eine Fragerunde, wo sich alle Ihre Fragen beantworten werde, die Sie in diesem Chat stellen. Dann fangen wir auch schon kurz mal an, wir würden grundsätzlich in 2019 gegründet, sind ein Kleinunternehmen aus Berlin, haben mittlerweile 20 Mitarbeiter, ein Großteil davon natürlich in der Technikabteilung.
Florian Polak: 00:03:09,050 –> 00:03:51,800
Haben da eigene KI Spezialisten, die sich in den letzten vier, fünf Jahren eigentlich damit beschäftigt haben, solche Algorithmen und aber auch natürlich Infrastruktur dafür aufzubauen, mit dem Fokus immer mehr einer Analyse von Gesprächen, aber auch Texten gut hinbekommen. Wir haben uns fokussiert, Da wir ja als deutsches Unternehmen mit auch sehr öffentlichen oder sehr großen Unternehmen zusammenarbeiten, haben wir uns darauf fokussiert, eben auf sensible Informationen zu verarbeiten mit dem entsprechenden Sicherheits und Datenschutzstandards, die damit einhergehen, und haben hier aber auch in der Marktforschung mittlerweile auch recht große Kunden. Was kann man mit unserer Software machen? Ganz grob gesagt sind es drei Bereiche.
Florian Polak: 00:03:52,010 –> 00:04:38,180
Das eine ist im Prinzip Online Communities auswerten, das heißt wirklich Fragen an große Datenmenge zu stellen. Dann natürlich die qualitative Kodierung von Kern, von Interviews oder Gruppenstudien und natürlich auch vor allem bei frei Textnennungen, also Textdaten, im Prinzip Excel oder Textdateien quantitativ im Prinzip auszuwerten, wann immer Sie eine Freitagsnennung haben, das möglich auf einen einzelnen Code zu verdichten und dann im Prinzip das Ganze auszuwerten. Ähm, ja, grundsätzlich unsere. Wir haben einige Kunden hier in Deutschland mittlerweile die größten, die wir haben, ist einerseits die deutsche Bundeswehr, aber auch im Automobilsektor. Recht viel ist mittlerweile mit Porsche und Mercedes Benz und im öffentlichen Bereich vor allem auch natürlich Landtag.
Florian Polak: 00:04:38,180 –> 00:05:18,290
Mecklenburg Vorpommern ist einer unserer größten Kunden hier. Grundsätzlich die drei Bereiche. Was kann man da genau machen? Im qualitativen Forschungsbereich geht es vor allem darum, Interviews oder Gruppendiskussionen im Prinzip zu einerseits zu transkribieren, da damit haben wir ursprünglich mal angefangen haben eigene Spracherkennungsalgorithmen aufgebaut, wie Sie es vielleicht hören. Ich bin Österreicher, der auch verschiedene. Im Prinzip Akzente und Dialekte kann unser Algorithmus ganz gut verstehen. Das Ganze wird in Text gebracht und dann geht es darum, im Prinzip anhand eines Leitfadens oder Ihrer Fragen im Prinzip relevante Antworten zu extrahieren und zusammenzufassen und wieder zu verdichten. Das selbe Thema dann auch in der quantitativen Forschung.
Florian Polak: 00:05:18,290 –> 00:05:56,180
Hier geht es vor allem darum, dass man wirklich große Mengen von Antworten hat, also beispielsweise Kundenservice ist ein klassischer Fall, wo dann sehr, sehr viele Antworten in alle Richtungen natürlich gehen, wo man diese Textendungen dann verdichtet, im Prinzip mit einem entweder bestehenden Codeplan oder aber auch die KI tatsächlich selber Code Pläne finden zu lassen. Im Durchschnitt braucht es unser System für so circa 1000 Freitagsnennungen unter zwei Minuten. Das geht also relativ fix. Das Ganze dann natürlich die Community so auswerten. Da geht es dann darum, dass wir viele, viele verschiedene Daten haben. Also sie können diese Daten entweder bei Excel hochladen oder aber auch per API Schnittstelle mit unserem System.
Florian Polak: 00:05:56,720 –> 00:06:38,450
Und dann können Sie Fragen im Prinzip an diese Datenmengen stellen, um dann relevante Ergebnisse im Prinzip zu extrahieren. Mehr dazu ein bisschen später. Verschiedenste Formate funktionieren bei uns Audio Videodateien, Excel wie schon erwähnt bzw. Maschinen lesbarer Text kann angeschlossen werden. Das Ganze natürlich auch eben als Schnittstelle mit Ihrem System. Wir haben ein paar Garantien, die wir Ihnen geben. Das eine Thema ist Anti Halluzination, da komme ich gleich nachher noch kurz darauf zu sprechen, was das eigentlich ist und wie man das dagegenstellen kann, dass wir im Prinzip ihnen helfen, eigentlich, dass unsere KI die relevanten Ergebnisse aus den Textmengen oder Datenmengen auch extrahiert.
Florian Polak: 00:06:38,900 –> 00:07:17,930
Dann garantieren wir Ihnen auch, dass die Daten ausschließlich in Deutschland verarbeitet werden. Da gibt es mehrere Varianten zusammenzuarbeiten. Wir haben unsere Server grundsätzlich Berner Anbieter namens Hetzner. Das heißt, wenn Sie mit unserer Cloud zusammenarbeiten, wird das ausschließlich auf diesem Server verarbeitet. Oder wir können sogar unser gesamtes System bei Ihnen auf dem Server installieren. Haben wir bei sehr großen Kunden schon auch gemacht. Einfach damit die Daten ihr System einfach gar nicht mehr verlassen. Dann natürlich, dass die Daten von unseren Kunden ausschließlich ihnen zur Verfügung stellen. Also sowohl die Extrakte im Prinzip, die Sie mit unserer Query rausbekommen, als natürlich die Daten, die Sie bei uns hochladen.
Florian Polak: 00:07:18,170 –> 00:07:58,670
Wir nutzen Ihre Daten nicht zu Trainingszwecken, außer natürlich, das ist gewünscht. Also wir können auch im Prinzip speziell für Ihren Fall dann natürlich auch ein eigenes Datentraining durchführen. Und last but not least, wenn Sie sehr, sehr große Datenmengen haben Sie haben bei uns keine Begrenzung an hochgeladenen Daten, das heißt, Sie können da wirklich rein jagen, was auch immer Sie da drinnen haben, weil und kriegen trotzdem ein sehr performantes Ergebnis, werde ich nachher kurz noch mal ein bisschen was dazu sagen, dass Sie auch bei großen Datenmengen tatsächlich relevante Ergebnisse sehr präzise rausbekommen. Gut, dann steige ich auch schon ein mit Problemen grundsätzlich bei Studie Auswertung von Studien mittels KI.
Florian Polak: 00:07:59,570 –> 00:08:39,169
Das Hauptthema ist das Thema Halluzination. Also im Prinzip wirklich, dass die KI Ergebnisse bringt, die eigentlich nicht relevant sind. Um auf die Frage, die sie gestellt haben wir Es gibt da verschiedene Mechanismen, die man entgegenwirken kann. Ich werde nachher kurz ein bisschen was dazu sagen, was das eigentlich ist oder was üblicherweise die. Die Gründe dafür sind dann ein sehr, sehr wichtiges Ergebnis. Ich weiß nicht. Ich nehme mal an, dass viele von Ihnen schon mittlerweile mit Start up oder ähnlichen KI Systemen gearbeitet haben. Grundsätzlich gibt es geht es ja auch teilweise jetzt schon ganz gut. Allerdings sind im Regelfall gerade bei großen Datenmengen die Ergebnisse relativ ungenau oder unpräzise und eher oberflächlich.
Florian Polak: 00:08:39,590 –> 00:09:19,370
Dafür gibt es ganz gute Gründe, zu denen ich auch gleich noch ein bisschen was sagen werde. 121 anderes Thema natürlich. Je nachdem, in welchem Anbieter sie arbeiten, werden Daten teilweise zu Trainingszwecken weiterverwendet, weil die Systeme erst im Prinzip im Aufbau sind oder sich ständig weiterentwickeln. Oder die Daten werden natürlich in Anbieter an die USA weiter übermittelt. Als Beispiel wäre da zB IT zu nennen und beispielsweise das ist natürlich ein großes Risiko, weil ihre sensiblen internen Daten dann eventuell in zukünftigen Modellen im Prinzip als Antwort auch rauskommen können, was natürlich nicht in ihrem Interesse ist. Und sie haben sich auch schon ein bisschen was darüber gehört über das Thema Tokens.
Florian Polak: 00:09:19,880 –> 00:10:22,610
Und grundsätzlich trugen sie es in der Art und Weise, wie an solche Komodelle im Regelfall abrechnen oder bzw. wie. Wie viele Informationen auf einmal verarbeitet werden können. Das Man kann sich unter einem Token ungefähr ein Wort vorstellen, Das heißt, wie viele Wörter können von der KI gelesen werden? Da gibt es Limitierungen. Grundsätzlich. Zwar werden diese Kontextwindows im Prinzip also die Art, die Anzahl an Wörtern, die sie einspielen können, zwar immer größer, trotzdem haben sie da immer noch eine Limitierung, die natürlich nicht gewünscht ist. Wenn man große Datenmengen also von einer ganzen Studie beispielsweise auswerten möchte. Und eines der wichtigsten Themen für uns ist im Prinzip Nicht nur die tatsächlichen Ergebnisse der KI sollten angezeigt werden, sondern auch tatsächlich die Originalzitate, also die Originaltext stellen aus den Studien, die nämlich auch relevant sind, um vor allem den Kontext besser zu verstehen, aber auch natürlich, um zu überprüfen, ob die Antwort der KI tatsächlich richtig ist oder ob es sich beispielsweise um eine Halluzination handelt.
Florian Polak: 00:10:22,820 –> 00:11:03,950
Das sind so die wichtigsten Themen eigentlich in diesem Bereich. Ich werde mal kurz erzählen, grundsätzlich, was für Technologie sich hinter TTP versteckt. Es handelt sich um etwas, das nennt sich Large Language Model. Es sind verschiedene Arten von Modellen, aber im Prinzip basiert eigentlich alles auf dieselbe Art und Weise. Ist im Prinzip ein Modell, das gemacht wurde, um Sätze zu vervollständigen, basierend auf Wahrscheinlichkeit, das heißt, basierend auf dem Kontext, den Sie als Frage stellen, und dem Kontext, den Sie beispielsweise als Studie in das System hineinspielen. Versucht die ZBD beispielsweise die, den Satz zu vervollständigen, so dass er möglichst akkurat ist.
Florian Polak: 00:11:06,110 –> 00:11:45,920
Man muss sich darunter vorstellen Diese ganzen großen Land Language Modellen wurden mit Milliarden und Milliarden von Daten im Prinzip gefüttert. Das heißt, sie haben Milliarden von Daten im Prinzip gesehen und Sätze gelesen und können dann aufgrund dieser Trainingsdaten im Prinzip Sätze vervollständigen. Das ist im Wesentlichen eigentlich, was die Technologie hinter JPC ist. Das bedeutet natürlich, dass diese Systeme manchmal ist die wahrscheinlichste Antwort die korrekte. Das muss aber nicht immer der Fall sein. Das kann auch passieren, dass das System irgendwo abbiegt, die Frage zum Beispiel falsch versteht oder auch den falschen Kontext hat, um die Antwort im Prinzip zu generieren.
Florian Polak: 00:11:46,100 –> 00:12:25,880
Und dann passiert etwas, was im Umgangssprachlichen mittlerweile Halluzinieren genannt wird. Das ist im Prinzip ein Sammelbegriff für viele verschiedene Probleme. Das ist im Regelfall der Hauptgrund ist darauf, dass die KI im Prinzip. Auf die falschen Daten zurückgreift und dann im Prinzip die falschen Informationen liefert, um die Frage zu beantworten. Aus Nutzerperspektive ist es natürlich Sie stellen eine Frage, wollen eine Antwort haben und das System liefert Ihnen eine völlig falsche Antwort, was objektiv falsch ist und im Prinzip dann unter Halluzinieren zusammengefasst wird. Letztes Thema, was auch sehr, sehr wichtig ist, Wo ich gerade vorhin erwähnt habe, diese Kontextwindows oder auf deutsches Kontextfenster.
Florian Polak: 00:12:25,910 –> 00:13:01,730
Das ist im Prinzip schon ein bisschen ein Markttrends von den großen, laut Language Modellen sehr großen KIs, die im Moment am Markt sind. Die Idee der ganzen Sache ist, möglichst viele Daten auf einmal in das System einspielen zu können, um dadurch einen besseren Kontext für die KI zu generieren. Dadurch, dass das somit die Fragen dann besser beantwortet werden können. Die größten Modelle, die aktuell am Markt sind, sind meines Wissens nach das von Google, wo fast 1 Million solcher Tokens im Prinzip auch gleichzeitig verarbeitet werden können. Sie können da ein ganzes Buch reinschmeißen und dann im Prinzip Fragen an dieses Buch stellen.
Florian Polak: 00:13:02,720 –> 00:13:36,980
Problem bei der ganzen Sache ist, dass erstens mal ist es ein recht ineffiziente System, weil jedes Mal, wenn Sie eine Frage stellen an diese Daten, muss das gesamte Buch neu analysiert werden, was eine sehr ineffiziente Art und Weise ist. Und zwar sind diese Modelle zwar mittlerweile immer billiger, aber sie haben immer noch das Problem, dass wenn sie sehr, sehr viele Fragen stellen wollen, was bei Studien häufig vorkommt, dass ihnen dann ziemlich viel Kosten entstehen können. Und das zweite ist, was wahrscheinlich noch viel wichtiger ist Nur weil Sie einen größeren Kontext haben, heißt das nicht, dass die Antwort besser wird.
Florian Polak: 00:13:37,640 –> 00:14:14,030
Unbedingt. Zwar wird das System einen größeren Kontext haben und wird besser verstehen, um was es hier eigentlich geht. Also was hier die Studie zum Beispiel ist, heißt aber nicht, dass es eine präzise Antwort geben wird. Da komme ich ja schon zum nächsten Punkt. Warum sind denn solche KI Antworten manchmal so oberflächlich? Hintergrund der ganzen Sache ist, dass diese KIs im Prinzip darauf trainiert sind, möglichst natürlich richtige Aussagen zu treffen und keine falschen Antworten zu liefern. Eine Methode, um so was zu machen, ist im Prinzip den Kontext, die Kontextfenster zu erhöhen und mehr Daten reinzuspielen, um mehr Informationen zu zu liefern.
Florian Polak: 00:14:14,540 –> 00:14:58,820
Das Problem mit der ganzen Sache ist, dass das System darauf trainiert ist, bloß keine Fehler zu machen und bloß keine falschen Antworten zu liefern. Und aus diesem Grund im Prinzip versucht, eine Antwort zu generieren, die möglichst allgemeingültig ist und ja nicht falsch ist und in dem Kontext eben richtig ist oder und und und lieber eine oberflächliche Antwort gibt, als dass es einen tatsächlichen Fehler macht. Und das ist im Prinzip auch der Grund, warum dann im Prinzip seine Antwort relativ oberflächlich und ja allgemeingültig, aber vielleicht nicht besonders hilfreich für eine Studie ist. Was zur Folge hat das, dass diese Systeme tatsächlich in manchen Studien einfach gar nicht richtig oder gut eingesetzt werden können.
Florian Polak: 00:14:59,900 –> 00:15:41,120
Das ist so das Hauptthema. Das heißt, man muss sich ein bisschen bei diesen gängigen KI Systemen überlegen. Geht man das Risiko ein, dass das Ding halluziniert oder möchte man lieber oberflächliche Antworten haben? Und das ist im Prinzip das Hauptthema, was gerade am Markt mit diesen KI Modellen das problematisch ist. Wir gehen ein bisschen in eine andere Richtung und wir haben. Grundsätzlich werde ich ein bisschen erzählen, wie wir die Infrastruktur hinten aufgebaut haben, um genau diese beiden Probleme nicht zu haben, sondern um wirklich sehr, sehr tief reinzugehen, sehr, sehr präzise Antworten zu generieren, auch bei sehr großen Datenmengen, ohne das Problem zu haben, dass wir auf der anderen Seite Halluzinierung Stimmen haben oder die Antworten einfach sehr generisch sind.
Florian Polak: 00:15:42,980 –> 00:16:30,260
Im Prinzip Was macht unsere KI eigentlich oder was macht das System dahinter? Wir haben einen Text hier im Beispiel ist es jetzt ein Transkript. Wir haben zum Beispiel einen Audiofall von Ihnen bekommen. Das wurde von uns transkribiert. Das heißt, wir haben ein Wortprotokoll des Interviews und jetzt geht unser System über diesen Text und bricht diesen Text auf in Themenblöcke. Das heißt, es nennt sich im Fachsprache nennt sich das Ganze Junking, Das heißt im Prinzip wir wir. Ein System geht über diesen Text und schaut sich an, wo beginnt ein Thema und wo hört es wieder auf und generiert dann ebensolche solche Inhaltsblöcke und bricht diesen langen Text, der ja auch bei einer Stunde Interview mehrere 20 30 Seiten lang sein kann, in kleine Blöcke auf, die dann wiederum abgelegt werden in einem eigenen Datenbanksystem.
Florian Polak: 00:16:30,260 –> 00:17:12,619
Das Datenbanksystem nennt sich Vektor Datenbank. Es ist im Prinzip ein Datenbanksystem, das gut geeignet ist, Inhalte miteinander zu vergleichen. Das heißt, man kann sich vorstellen, ein ganzes Interview wird aufgebrochen. Man hat dann beispielsweise 1000 solche Themenblöcke und diese Themenblöcke werden dann auf dieser Datenbank als Graphen, also in einen mathematischen Wert umgewandelt und auf diese Datenbank abgelegt. Wenn Sie jetzt eine Frage haben und beispielsweise wissen wollen okay, fanden die Teilnehmer. Immer den Kunden Service gut und das System wird diese Frage wiederum analysieren. Um was geht es hier in Aufbrechen in so einen Themenblock und diesen Themenblock ebenfalls auf diese Vektordatenbank ablegen.
Florian Polak: 00:17:13,700 –> 00:17:56,060
Jetzt hat man diese zwei Themenblöcke und das System ist ganz gut geeignet zu vergleichen, Wie nah sind die aneinander dran? Das heißt, das System sucht dann auf Ihre Antwort alle relevanten Stellen in diesem Transkript raus, die geeignet sind, um Ihre Frage zu beantworten. Und diese Textblöcke werden dann genommen, werden dann eben so eine KI weitergegeben, die nicht mehr das ganze Transkript liest, sondern ausschließlich diese Themenblöcke. Daraus dann im Prinzip eine Antwort generiert und ihre Frage beantwortet hat zwei Vorteile Nummer eins Wir, die grundsätzlich. Die Antwort ist sehr, sehr präzise, weil sie im Prinzip wirklich ausschließlich den Text liest, der relevant ist, um Ihre Frage zu beantworten.
Florian Polak: 00:17:56,720 –> 00:18:30,620
Und das Zweite ist Wir können eine Rückverfolgbarkeit von Informationen garantieren. Das heißt, wir zeigen Ihnen grundsätzlich nicht nur einfach nur die Antwort der KI an, sondern wir zeigen Ihnen auch alle Textblöcke an, die relevant waren, um diese Frage zu beantworten. Und auf einmal können wir eine Rückverfolgbarkeit garantieren, was zur Folge hat, dass wir nicht nur Ihre Frage beantworten können, sondern sie das Ganze auch einfach überprüfen können. Das ist im Prinzip unser System und wir haben jetzt verschiedene Anwendungsfelder, wo wir das im Prinzip einsetzen. Erstes Thema ist beispielsweise bei diesem Kodieren von offenen Antworten in quantitativen Studien.
Florian Polak: 00:18:30,740 –> 00:19:15,890
Also beispielsweise Sie haben 1000 Antworten von Teilnehmern einer Onlinestudie, die im Prinzip einfach Informationen geben, was Sie zu dem Kundenservice gesagt haben. Jeder dieser Aussagen wird im Prinzip jetzt wiederum selbes Prinzip aufgebrochen in diese Themenblöcke. Manchmal ist so eine Antwort ja durchaus sehr, sehr lange. Dann sind es dann mehrere Themenblöcke, die werden wiederum abgelegt und die Codes, die im Prinzip genutzt werden, um das Ganze zu verdichten, werden ebenfalls als Themenblöcke abgelegt. Und dann wird eigentlich nur noch miteinander verglichen Was passt gut, welche Codes passen gut zu dieser Aussage? Und so kann man diese Ergebnisse relativ schnell verdichten, ohne die Gefahr zu gehen, dass die Ergebnisse falsch zugeordnet werden.
Florian Polak: 00:19:17,390 –> 00:19:58,070
Natürlich kann man da relativ lange Studien einfügen. Also die größten, die wir jetzt mittlerweile haben, waren glaube ich 20.000 Textnennungen, die dann im Prinzip dort nur System durch gejagt wurden. Verschiedene Datenformate unterstützen wir. Klassisch sind natürlich Excel oder SS, da dann das ganze Thema wird einfach einmal durch codiert. Das dauert im Durchschnitt für so 1000 Nennungen zirka zwei Minuten. Man kann sich die Ergebnisse natürlich wieder anschauen, kann eventuell auch nachbessern, wenn man das möchte, also einen anderen Code zum Beispiel verwenden. Oder man kann sogar dem System sagen, hier sind alle Nennungen, finden wir einen guten Code bei, nachdem ich das Ganze verdichten kann drüben.
Florian Polak: 00:19:58,520 –> 00:20:45,780
Und das Ganze im Prinzip dann durch Codieren lassen. Und die Formate können dann wieder als Excel oder SSDatei wieder exportiert werden. Das nächste Thema ist eher in der qualitativen Forschung. Hmmm. In der qualitativen Forschung geht es mir darum, Interviews oder Gruppendiskussionen tatsächlich zuerst einmal in Text zu transkribieren. Da haben wir Verschiedenes, verschiedenste Spracherkennungsalgorithmen für die verschiedenen Sprachen. Im Regelfall können wir alle romanischen Sprachen gut abdecken. Wir können vor allem im Deutschen, wo unser Fokus liegt, auch die verschiedenen Dialekte und Akzente auch ganz gut im Prinzip kennen. Je nach Aufnahmebedingungen schaffen wir da im Durchschnitt circa 95 % Genauigkeit.
Florian Polak: 00:20:45,780 –> 00:21:34,050
Das entspricht einer geschulten Transkriptionspersonen, die im Prinzip daneben sitzt und jedes Wort mitprotokolliert. Dann haben Sie mal den. Das Wortprotokoll, also im Prinzip das Transkript des Interviews oder der Gruppendiskussion. Und wenn es sich um eine Gruppendiskussion handelt, kann zum Beispiel dann automatisch auch das Gespräch nach Sprechern aufgebrochen werden. Das heißt, wenn Sie beispielsweise fünf Leute zu einem Thema befragen, wird dann schon aufgebrochen nach Sprecher, ein Sprecher, zwei Sprecher, drei Sprecher vier und fünf natürlich. Und sie können nachher dann wiederum, weil das System das Ganze dann aufbricht, wiederum sich aussuchen. Okay, möchte ich eine Analyse über alle Teilnehmer machen oder möchte ich wirklich tatsächlich einfach für jeden Sprecher relevante Informationen rausziehen?
Florian Polak: 00:21:35,250 –> 00:22:16,650
Und das System gibt Ihnen dann im Prinzip die Antworten auf Ihre Fragen. Das kann zum Beispiel der Leitfaden sein, den Sie hinterlegen oder auch Ihre Research fragen, um spezifisch nach bestimmten Informationen zu suchen. Das Spannende der Sache ist Sie können ein Interview hochladen und das analysieren. Oder Sie können ein ganzes Studio hochladen, um viele verschiedene Informationen aus den beispielsweise zehn Interviews rauszuziehen, um dann gemeinschaftlich einfach sich ein Bild zu machen über diese verschiedenen qualitativen Studien, die Sie da durchgeführt haben. Und der letzte Punkt ist wirklich tatsächlich, dass wir unser neuestes Modul eigentlich, dass wir tatsächlich große Mengen an Daten im Prinzip anbinden können.
Florian Polak: 00:22:16,650 –> 00:23:03,240
Ein klassisches Beispiel wären zum Beispiel Social Media Kanäle, die Sie per API Schnittstelle zum Beispiel anschließen können, um dagegen dann Fragen zu stellen. Sprich da werden Datenpunkte im Prinzip von Ihnen in unser System eingespielt, maschinenlesbar. Der Text muss das Ganze sein und dann können Sie tatsächlich Ihre Fragen gegen diese Datensätze stellen. Das können Exceldateien sein, das können Textdateien sein, über eine API zum Beispiel. Das können aber auch Transkripte von Interviews natürlich sein, um dann wirklich eine gesamt einheitliche Auswertung über diesen diese ganze Studie zu machen. Wunderbar geeignet natürlich für andere Communities, wo es grundsätzlich relativ viele Daten gibt, wo auch über mehrere Tage oder Wochen hinaus gewisse Informationen gesammelt werden von Usern, um dann wirklich so eine Auswertung tatsächlich zu machen.
Florian Polak: 00:23:03,870 –> 00:23:55,080
Das System zeigt ihnen dann immer die Antwort an, aber auch die Referenzen wirklich von den jeweiligen Textblöcken wiederum woher die Informationen eigentlich kommen, sodass sie dann leicht eine Möglichkeit haben, das Ganze zu überprüfen. Genau. Als Epischnittstelle können Sie das natürlich anschließen. Ähm, grundsätzlich wie funktioniert unser System? Gibt grundsätzlich mal zwei Möglichkeiten, wieder zusammenzuarbeiten. Wir können das Ganze bei Ihnen auf dem Server installieren. Das wäre dann so eine On Premise Installation. Das heißt, dann wird das Ganze wirklich auf Ihren Server betrieben. Keine Daten verlassen Ihr Unternehmensnetzwerk. Der einzige Nachteil, den Sie da haben, abgesehen davon, dass es ein bisschen umständlich ist, ist, dass Sie da relativ starke Server brauchen, inklusive solche Grafikkarten, also GPUs genannt, die geeignet sind, im Prinzip, um diese Systeme sehr performant laufen zu lassen.
Florian Polak: 00:23:55,470 –> 00:24:39,750
Oder sie entschließen sich, das Ganze auch mit uns zusammenzuarbeiten in der Cloud. Da garantieren wir Ihnen wie gesagt, dass die Daten ausschließlich in Deutschland verarbeitet werden. Das ist dann im Prinzip auf unserem Server, der in Nürnberg steht. Serveranbieter ist ein deutsches Unternehmen namens Hetzner und wo im Prinzip dann die Daten analysieren zu lassen. Ähm, grundsätzlich natürlich sind diese Systeme hinreichend gesichert, sprich wir verarbeiten ihre Daten auch wirklich nur so, wie sie das Ganze von uns wünschen. Gibt da verschiedene Möglichkeiten, wie wir zusammenarbeiten können. Man kann auch eigene Datentrainings für sie machen, wenn sie das wünschen. Und es gibt natürlich auch die Möglichkeit in anderen EU Ländern beispielsweise einen Cloudserver aufzubauen, was wir grundsätzlich auch schon in der Vergangenheit gemacht haben.
Florian Polak: 00:24:41,390 –> 00:25:18,530
Zu den Preisen gibt es zwei verschiedene Art und Weise, mit uns zusammenzuarbeiten. Das eine Thema wäre wirklich so einer on demand. Das heißt wirklich, Sie haben ein Projekt, Sie kommen auf uns zu und sagen, wir wollen jetzt dieses Projekt mit ihnen durchführen. Wir machen ein Angebot und rechnen dann nach der Studie im Prinzip ab. Da rechnen wir grundsätzlich immer nach Datensätzen ab, also im Prinzip, wenn es sich um qualitative Interviews handelt. Das rechnen wir meistens über Audiostunden ab. Wenn es sich um Excel Dateien handelt, die abgerechnet werden müssen, haben Sie, zahlen Sie einen Cent pro Betrag für eine Pro Excel Zelle, also pro Nennung des Befragten und rechnen das Ganze völlig flexibel ab.
Florian Polak: 00:25:18,530 –> 00:25:54,140
Keine Bindung, oder? Wir haben auch natürlich das Corporate Offer. Das machen wir bei größeren Kunden mit uns, dass sie einen jährlichen Fixpreis haben, dann haben sie keine Mengeneinschränkung, können das Ganze mit uns machen nach Lust und Laune und können auch bauen das Ganze für sie im Prinzip dadrauf. Das kann natürlich auch alles kombiniert werden. Das heißt, es gibt natürlich auch die Möglichkeit, dass man zum Beispiel eine qualitative Studie durchführt, die Ergebnisse dann verdichtet. Im Prinzip. Beispielsweise im Quantenmodul, dass man dann wirklich das Ganze auf wirkliche Wortnennungen verdichtet und das Ganze kodiert, um dann eine sehr, sehr gute Auswertung zu kriegen.
Florian Polak: 00:25:54,140 –> 00:26:31,070
Und um sich einen Report im Prinzip schnell herzurichten. Das wäre auch schon alles von meinem Webinar. Jetzt würde ich ganz kurz auf die Fragen eingehen, die Sie grundsätzlich hier im Chat gestellt haben. So gibt es die Möglichkeit, Audiodateien zu testen zu lassen. Starke Dialekt aus Österreich zum Beispiel. Ja, grundsätzlich. Sie können das bei uns auch immer alles testen. Das heißt da einfach uns gerne unverbindlich einfach schreiben. Wir bieten natürlich immer die Möglichkeit an, das Ganze auszuprobieren, sei das jetzt eben bei Audiodateien mit Akzenten zum Beispiel, aber auch natürlich bei Excel Studien, dass Sie das mal ausprobieren können und sich von der Qualität überzeugen.
Florian Polak: 00:26:31,880 –> 00:27:11,870
Bei den Akzenten Grundsätzlich gilt je in Österreich vor allem je weiter östlich, desto leichter, je weiter westlich, desto schwieriger. Schweizer Akzente und Dialekte sind tatsächlich ein bisschen problematisch, weil es keine keine einheitliche Art gibt, wie man Schweizerdeutsch schreibt. Deswegen gibt es auch wenig Möglichkeiten, da leicht einen Spracherkennungsalgorithmus aufzubauen. Wir haben aber schon die verschiedensten Projekte auch in Österreich gemacht. Sprich einfach kontaktieren und einfach ausprobieren, würde ich vorschlagen. Dann die nächste Frage war dann auch noch Können auch Transkripte von Face to Face Gruppendiskussionen mit Zuordnung der sprechenden Person gemacht werden oder nur von anderen Gruppen? Face to face geht auch.
Florian Polak: 00:27:11,870 –> 00:27:53,330
Wir brauchen grundsätzlich eine Aufnahme in einer Art oder oder der anderen. Also beispielsweise, wenn Sie wirklich eine Face to Face Studie haben und das Ganze aufnehmen, können Sie nachher die Audiodateien nehmen, hochspielen und das Ganze dann im Prinzip transkribieren lassen. Wir wir machen das nicht über die verschiedenen Kanäle, also beispielsweise bei einem Online Meetings über Teams gibt es ja die verschiedenen Sprecherkanäle und im Regelfall hat man bei der Transkription dann so eine Aufteilung nach den verschiedenen Kanälen. Wir machen das Ganze über eine eigene Sprechererkennung, das heißt, wir haben da einen eigenen Algorithmus drinnen, der die Unterschiede in den Stimmlagen erkennt und das Gespräch danach im Prinzip auf aufbricht, quasi.
Florian Polak: 00:27:54,260 –> 00:28:28,400
Bedeutet aber natürlich auch, dass das wir nicht wissen, dass ich zum Beispiel der Florian Pollack bin, sondern wir wissen eigentlich dann auch nur okay. Es gab fünf Sprecher in diesem Gespräch und folgender Sprechereinsatz folgende Sachen gesagt natürlich, wenn man nachher die Informationen wieder braucht, um eine Analyse zu fahren, beispielsweise, dass man die Analyse machen möchte, über was die weiblichen Teilnehmer der Studie gesagt haben, dann kann man diese Referenzen wieder einfügen. Das müsste dann manuell im Nachhinein gemacht werden von Ihnen, geht aber recht schnell, um dann nachher im Prinzip in der Auswertung auf der Ebene auch noch machen zu können.
Florian Polak: 00:28:29,840 –> 00:29:11,360
Haben Sie auch Familien mit Schweizer deutschen Dialekten? Ja, haben wir. Schweizerdeutsche Dialekte sind leider etwas schwierig, muss ich noch dazu sagen. Wir haben mittlerweile ein neues Modell, das glaub ich nächste Woche rauskommt, das tatsächlich für Schweizerdeutsch Ergebnisse bringt, die, sagen wir mal deutlich besser sind als das, was sie bisher am Markt kennen. Wir müssten dann allerdings auch ausprobieren, wie die wie die Qualität wirklich ist, weil das eben ein sehr, sehr neues Modell ist. Grundsätzlich ist das ein bisschen schwieriger natürlich als österreichisch oder oder deutsch Deutsch mit den verschiedenen Dialekten und Akzenten dort. Und dann kann man von Ihnen anonymisierte, pseudonymisierte Beispiele für eine Textauswertung erhalten, um ein Gefühl für die Ergebnistypen zu bekommen.
Florian Polak: 00:29:11,360 –> 00:29:52,440
Ja, können Sie, wenn Sie grundsätzlich mit uns machen. Meistens dann so eine Demo. Da haben wir auch eine Demostudie drinnen, wo Sie das Ganze sich einmal anschauen können und durchaus dann im Prinzip das Ganze auch verwenden können, um selber sich zu überprüfen, ob das System passt oder nicht. Dann kann die ja vorher die Webseite oder Dokumente crawlen und Spezialbegriffe Spezialabkürzungen zu identifizieren. Wir haben viele Fachbegriffe, die auch von Kunden verwendet werden. Grundsätzlich. Das Thema Spezialbegriffe ist immer wieder relevant. Für qualitative Studien ist es insbesondere dann relevant, weil die Spracherkennung basiert nämlich auch auf dem üblichen Sprachgebrauch.
Florian Polak: 00:29:52,860 –> 00:30:42,570
Wenn es dann Spezialbegriffe gibt, Eigennamen, Firmennamen beispielsweise. Sowas kann im Regelfall sehr, sehr einfach im Prinzip hochgeladen werden, in dem sie eigentlich ein Level hochladen, Ob wir es von der Webseite crawlen. Grundsätzlich einen Service. Wir haben theoretisch Crawler mit so was zu machen. Effizienter wäre es wahrscheinlich, wenn wir einfach im Prinzip sie uns die Webseite sagen. Wir schauen uns das Ganze für Sie an, erstellen wir eine Excelliste an diesen Fachbegriffen und laden die einmal hoch. Das dauert im Regelfall zwei drei Minuten, ist recht schnell gemacht und dann werden die Begriffe auch richtig erkannt. Üblicherweise, wenn es sich um Webbegriffe handelt, die auf Webseiten sind, macht es in der Textauswertung gar nicht mal so groß eine Rolle, weil die KI Systeme im Regelfall mit sehr, sehr großen Datenmengen gefüttert wurden, sodass auch Spezialbegriffe dann auch richtig erkannt werden.
Florian Polak: 00:30:42,570 –> 00:31:26,060
Also ein Kontext passt dann im Regelfall ganz gut. Insofern sollte das damit auch eher kein Problem sein. Und welche Sprachen können Sie abbilden? Alle europäischen und auch nichteuropäischen Sprachen. Grundsätzlich also was auf jeden Fall sehr, sehr gut funktioniert, sind die romanischen Sprachen, also Deutsch, Englisch, Französisch, Spanisch, Italienisch. Wir hatten dann aber auch Niederländisch, Dänisch, die auch gut funktioniert haben. Im Englischen natürlich die verschiedenen Sprachgruppen, die wir haben. Also wir hatten tatsächlich auch eine Studie, die mit singapurianischen Akzenten waren, wo ich in der Spracherkennung, also ich persönlich hätte weniger verstanden als unsere KI da tatsächlich. Also da gibt es auch die verschiedensten Möglichkeiten.
Florian Polak: 00:31:26,070 –> 00:31:56,130
Wir haben aber auch die Möglichkeit, wenn es, sagen wir mal, eine sehr exotische Sprache ist, die nicht sehr häufig vorkommt, hier noch mit anderen Anbietern zusammenzuarbeiten. Dann müssten wir uns aber im konkreten Fall anschauen, was sie da brauchen. Und auch da müssen wir uns genau noch mal erkundigen, wie das Ganze funktioniert, dass wir auch garantieren können, dass die Daten ausschließlich auf unserem Server verarbeitet werden, weil das dann halt eine Spracherkennung ist, die wir nicht anbieten, da gerne einfach auf uns zutreten. Wir können dann im Spezialfall gerne noch mal drüber reden, wenn wir schon beim Thema Sprache sind.
Florian Polak: 00:31:56,160 –> 00:32:42,570
Ein wichtiger Punkt geht auch Beispiel insbesondere bei qualitativen Studien. Sie können auch im Prinzip, wenn Sie einen Leitfaden beispielsweise auf Deutsch haben und die Studien mehrsprachig sind, also beispielsweise auf Englisch und auf Deutsch, dann können Sie das Ganze transkribieren lassen, auf Englisch und jeweils auf Deutsch und dann aber den Leitfaden nehmen, um den auch auf die englischen Transkripte gegen die zu stellen, sodass die Antworten aus dem Kontext, aus dem englischen Transkript raus extrahiert werden, um dann im Prinzip aber auf Deutsch übersetzt werden. Das funktioniert. Es ist genaugenommen kein Übersetzungsprogramm, sondern es ist, dass die KI versteht den Kontext der anderen Sprache, weil die Trainingsdaten in sowohl auf Englisch als auch auf Deutsch zur Verfügung waren.
Florian Polak: 00:32:42,840 –> 00:33:17,060
Das funktioniert erstaunlich gut. Das heißt, Sie können auch mehrsprachige Studien mit uns durchführen, ohne weitere Probleme. So, dann die nächste Frage Können mehrere Sprachen gleichzeitig verboten werden? Ja, das war kurz die Frage, die ich gerade beantwortet haben. Also zum Beispiel für Studien in Belgien. Ja, das geht grundsätzlich. Also wenn Sie eine französischsprachige Studie haben und das andere wäre Flämisch, zum Beispiel, sollte das kein Problem sein, müssten wir das einmal transkribieren in die jeweilige Sprache. Und wenn Sie dann Ihren Leitfaden aus auf beispielsweise Deutsch haben, werden die Antworten im Prinzip genutzt, um dann ein Ergebnis zu produzieren.
Florian Polak: 00:33:17,070 –> 00:34:08,850
Also Ihre Antwort zu der Frage zu beantworten. Wenn Sie denn die Zitate haben wollen, sind die dann logischerweise aber in der Originalsprache. Und die letzte Frage Können bei quantitativen Studien demografische Daten mit offenen Ländern verknüpft werden dann die Texte danach analysiert, also zum Beispiel bei Männern ist es so und bei Frauen ist es so, Ja, das geht also grundsätzlich. Das wäre dann am ehesten unser letztes Modul, von dem ich gesprochen habe, dieses hier, dass Sie dann eine ganze Excel hochladen, wo dann die ganzen relevanten Datenpunkte drinnen sind und sie dann dagegen einfach die Fragen stellen. Also da können Sie dann auch eine Auswertung machen nach Geschlechtern, nach Informationen, die grundsätzlich in diesen Exceldateien drin sind, um relevante Ergebnisse zu machen, kann natürlich auch kombiniert werden mit den anderen Modulen, die wir haben, um dann so ein Excel zu produzieren, gegen das Sie dann im Prinzip Ihre Research Fragen stellen können.
Florian Polak: 00:34:10,320 –> 00:34:46,139
Okay, wunderbar. Dann waren das, glaube ich, alle Fragen. Hatte es noch eine Frage? Können Sie die Preise der Pakete bitte noch mal wiederholen? Wir haben. Jetzt kommt ein bisschen darauf an, in welcher Kombination Sie das Ganze machen wollen. Bei den Preisen gilt es grundsätzlich zwei Varianten zusammenzuarbeiten Entweder Abrechnung nach Projekten. Das heißt, Sie haben beispielsweise zehn Interviews, die Sie mit uns transkribieren und dann auswerten wollen und wir machen. Ich gebe Ihnen einen Preis, nachdem Sie das Ganze auswerten können und sie zahlen dann nach Durchführung des Projektes. Oder die Variante ist, dass Sie einen Pauschalpreis mit uns machen.
Florian Polak: 00:34:46,139 –> 00:35:17,370
Da kommt es wie gesagt darauf an, welche Funktionen Sie gerne haben wollen. Und dann machen wir einen Pauschalpreis pro Jahr. Und dann ist es uns auch egal, wie viele Studien Sie darüber laufen lassen. Kommt darauf an, in welchem Kontext Sie machen. Das Corporate aber macht im Regelfall dann Sinn, wenn Sie viele Datenmengen haben oder sehr, sehr viele Studien durchführen. Ansonsten würde ich Ihnen wahrscheinlich dazu raten, das Ganze auf Projektbasis Minus zu machen. Gut, dann vielen Dank, dass Sie heute ins Webinar gekommen sind. Wenn Sie grundsätzlich noch Fragen haben Sie können. Meine Emailadresse finden Sie hier unten.
Florian Polak: 00:35:17,820 –> 00:35:38,190
Sie können uns jederzeit natürlich auch schreiben. Grundsätzlich werden wir auch, glaube ich, eine Zusammenfassung von diesem Webinar auch nochmal zirkulieren. Die Zusammenfassung ist dann auch schnell generiert für unsere Studie. Dann haben Sie da auch schon mal einen Überblick, wie gut das System eigentlich erarbeitet und habe mich sehr gefreut, dass Sie heute gekommen sind. Und ich wünsche Ihnen noch einen schönen Nachmittag. Vielen Dank!
A Comprehensive Overview of Webinar Topics
The webinar provided attendees with a structured exploration of AI's role in market research, covering the following topics:
- The fundamentals of AI systems and their application in market research.
- Strategies for overcoming common AI integration challenges, with a focus on Tucan.ai's unique methodologies.
- An in-depth look at Tucan.ai's product suite, featuring case studies that demonstrate their problem-solving capabilities in real-world scenarios.
- The critical importance of data security in AI applications and Tucan.ai's unwavering commitment to client data protection.
Key Insights and Discussion Points
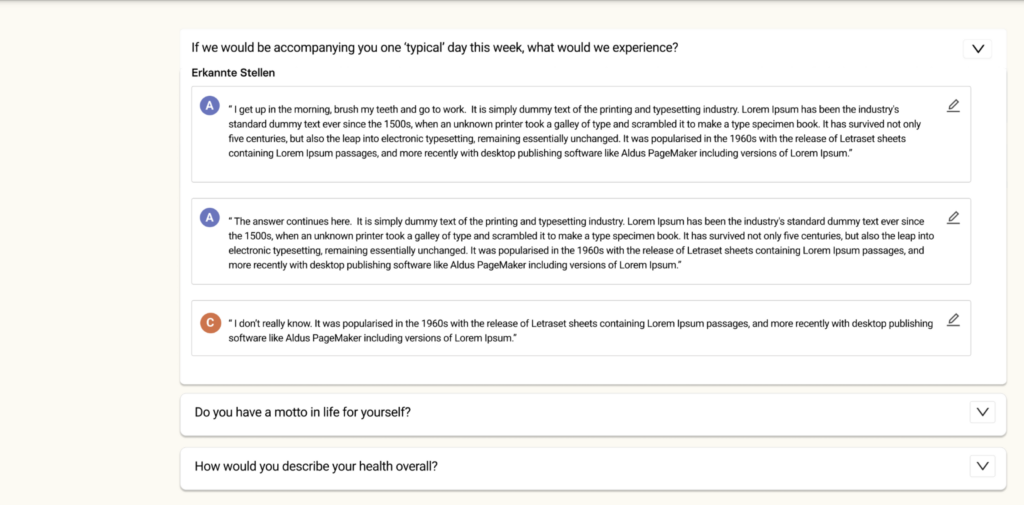
A highlight of the webinar was Florian Polak's explanation of "AI hallucinations." He used the analogy of a librarian to describe Tucan.ai's data chunking and vector databases, which ensure that the AI, like a skilled librarian, can efficiently sort through vast amounts of information to find the exact insights needed without distraction.
Practical Tips for Market Research Professionals
The webinar provided actionable advice, including:
- Implementing Tucan.ai's anti-hallucination features to validate AI-generated insights, with Polak emphasizing, "Accuracy is the cornerstone of our AI solutions."
- Applying AI for rapid coding of open-ended survey responses, transforming hours of manual work into a task that takes mere minutes.
- Utilizing Tucan.ai's multilingual capabilities to analyze diverse data sets, enabling comprehensive and inclusive research studies.
The AI Advantage
By addressing the specific challenges of market researchers with state-of-the-art AI solutions, market researchers not only can streamline their research process but also ensures more reliable and actionable insights. Whether it's for niche studies or a large-scale projects, AI tools can be tailored to meet the unique requirements of each research initiative.
Increase your productivity tenfold!

Fed up with low-quality AI tools for market researchers?
You are most likely reading this, because you are not satisfied with the solutions and technologies the AI hype has generated for market researchers.
And you shouldn't be.
Artificial intelligence was first envisioned as a technology, that would massively reduce the workload of humans, drive automation and enable new ways of working. ChatGPT has proven that AI is capable of assisting humans during work, but sophisticated industries like market research require more than just a beautiful front-end that links to a generalistic and basic service like GPT 3.5. Now, more than ever, there is a need for quality AI tools for market researchers.

But what is a quality AI solution?
The most valuable resource any market research firm has, is it's human capital and the unique minds that are capable of designing and evaluating intelligent studies. As such, the quality of a solution is decided by how powerful the support mechanisms of said solutions are. AI-platforms need to be non-intrusive, easy to use and should never infringe on a human's ability to have the last say in intellectual matters. At the same time, they should massively reduce time spent on rudimentary tasks and enable new ways of working.

tucan.ai - a proven AI platform for market research.
As our award for being the most innovative market research solution of 2023 shows, tucan.ai is a real AI-solution that was established well before the AI hype and uses proprietary algorithms and models. And because we are more than just a pretty mask for API calls to 3rd party providers, we are able to provide our services both online and offline and customize them to perfectly match the workflows, processes and IT-infrastructure of our partners. It comes as no surprise that some of the biggest market research firms across the globe are currently implementing our solution to ensure they stay ahead of the curve.

We enable qualitative researchers...
Our cutting-edge AI assistant allows you to get your interviews and focus groups encoded automatically on predefined categories or themes. In addition to the encoding of answers, researchers can define additional analysis tasks or datapoints they would like to extract from the data medium and receive results in mere minutes, whereas manually completing this task often takes the average researcher multiple days. Beyond market research, this function can also be used for opinion polling and similar fields that rely on qualitative data analysis. Learn more in our factsheet "AI-powered encoding with Tucan.ai" or contact us for a copy of the presentation we used for our viral "qualitative market research and AI" webinar.

...and quantitative researchers!
A recent addition and much requested feature of our existing market research customers, is the inclusion of functionalities that assist in quantitative market research. Our first release in this feature group allows you to analyze an unlimited number of datapoints based on a predefined code-plan or even ask the AI to create a code-plan for you. In our test, a researcher analyzed 400 datapoints with a partial code-plan. The AI assistant had the objective to complete the code-plan based on the given data and then quantify all entries based on all code-plan categories. The results were perfect and the entire process only took 1 minute and 43 seconds, all the way from opening our platform to opening the exported results. That is 228 times faster than even a fast researcher could have done it manually. To learn more about our new quantitative research features, contact us directly or sign up for our upcoming "quantitative market research and AI" webinar.
Contact us today and see how tucan.ai can transform your studies by enhancing every single workflow and enabling your researchers to 10x their results in a single month.

In case you wish to learn more about Tucan.ai's solutions for teams and enterprises, please schedule a short online call with our CEO, Florian Polak (florian@tucan.ai).
CUSTOMER VOICES
What they say about us
![]()
"We at Axel Springer have been using Tucan.ai for already over two years now, and we continue to be very satisfied with the performance of the software and the development process as a whole."
Lars
Axel Springer SE
![]()
"I have known the founding team for over a year. At Porsche, we are very satisfied with their work so far. I have recommended the use of Tucan.ai to my colleagues and business partners and I have been getting highly positive feedback back across the board - both on the service and the software."
Oliver
Porsche AG

"Tucan.ai has been a game-changer for our team. The software is incredibly intuitive and easy to use. It has saved us countless hours of work and has allowed us to focus on what really matters - our clients. I would highly recommend Tucan.ai to anyone looking for an AI-powered productivity tool."
Alex
Docu Tools
Tucan.ai helps revolutionize market research with smart encoding and archiving solutions

Winner of the startup pitch by Marktforschung.de, Norstat, GIM, ADM and BB Recruiting
Last April, the sixth Startup Pitch of marktforschung.de and Consulting.de took place, a Germany-wide online competition for market research, consulting and data analytics. Four startups from the fields of AI, UX, CX and data analytics were allowed to present their business ideas in front of an expert audience and a top-class jury. Fortunately, we made the running this year. With the following video our co-founder Florian Polak had introduced Tucan.ai in advance.
https://www.tucan.ai/wp-content/uploads/2023/06/Marktforschung.de_Video.mp4
The competition was supported by the industry association ADM, the personnel consultancy BB Recruiting, the institutes GIM and mindline, and the online field specialist Norstat. Sabine Menzel (L'Oréal), Janina Mütze (Civey), Jörg Kunath (mindline), Stephan Telschow (GIM), Arndt Schwaiger (Serial Entrepreneur), Christian Arndt (Hightech Gründerfonds), Birgit Bruns (BB), Roland Abold (ADM) and Sebastian Sorger (Norstat) sat on the jury. Marktforschung.de managing director Holger Geißler conducted a short interview with Sorger afterwards. Here you can read what the juror and CEO of Norstat had to say here in Germany:
Interview with Sebastian Sorger: "Those who can explain ideas simply have an advantage."
The participating start-ups were in very different stages. Can you even fairly compare a start-up like Gutfeel, which are about to enter the beta phase, with a start-up like Objective Platform, which already has a presence in three countries with 60 employees?
Sebastian Sorger: Yes. Basic things should be understandable in both phases: What is the business model? How is added value generated and monetized with the customer? What makes the market tick, the competition, what is the unique selling proposition?
I was surprised that few financials were mentioned by the startups compared to previous pitches. How do you rate that?
Sebastian Sorger: I felt the same way! Perhaps the promotional character towards the viewers was in the foreground?
What is exciting is: how large is the market realistically interested in the solution, how long is the sales cycle, and how can pricing work? Furthermore, how many early adopters or – if the company is mature enough – customers from the majority market could bite in order to be able to estimate sales revenues (and production costs). Fixed costs (personnel, travel, marketing, etc.) are deducted from this margin, and EBITDA can then be used to estimate how much capital is needed.
What are the milestones for the investment rounds? Of course, not everything is mentioned, but for example how high the funding was or should be, how much you want to collect now, when you want to reach break-even. Compared to a pure investor round, this information would certainly have come, or been demanded.
The maturity levels of the startups in terms of pitch presentations also varied widely. How crucial was it in your perception that Tucan.AI presented comparatively convincingly?
Sebastian Sorger: Florian from Tucan.AI managed to get the business model across very simply. What is the problem? How is the solution supposed to stop the problem? Everyone understood that.
I had the impression that Savio’s actually great business idea was not clear to everyone. How do you explain that Savio didn’t end up further ahead? Was it a disadvantage that Julian presented in English?
Sebastian Sorger: Maybe. Not everyone speaks and understands English equally well. I had the feeling Julian also focused too much on the text of the slides. I’m sure if he had let his passion run more freely, it would have been more infectious. However, it was also not clear until the end who its participants in this „two-sided-marketplace“ actually were.
You always pay a lot of attention to the founding team. What trends do you see there over the years? Are there generalizable trends?
Sebastian Sorger: They are often relatively young founders. That’s not bad at all. Often, experienced managers are brought in at a later stage to build structures and manage growth.
But I wonder when VCs / investors will realize that it can make a lot of sense to bring seniors on board right at the start. But then something has to change in the compensation model. „Only“ enticing with many shares is then simply not enough.
What other start-ups would be a good fit for the Norstat Group?
Sebastian Sorger: All those who usefully complement us in the field services for qualitative and quantitative research. They have a technology and we bring the participants and organize the whole shebang. The important thing here is that the start-up brings the customer with it; we are not the sales channel. Then we are up for (almost) any fun, as long as we follow the rules of the stand. With regard to M&A efforts, we tend to focus on established companies.
Tucan.ai webinar "AI coding of qualitative studies" on July 6, 2012 on marktforschung.de
As we have discovered through projects already underway with clients in this industry, coding interviews and focus groups is an extremely costly component of market researchers' day-to-day work. Tucan.ai takes care of the transcription, summary and coding of relevant content from conversations. The manual effort is reduced to a minimum by AI, without undermining the analysis and interpretation sovereignty of experts.
In this webinar, our key account manager Carlo Glaefeke will explain how Tucan.ai can help you reduce the time spent on qualitative studies by up to 80 percent. He will highlight the following points for you in detail, among others: Creating the guide, transcribing the interviews, coding the responses, and exporting the relevant data.
There are still some free places (it will be held in German, though)! Click here to register:
Article "Innovative AI tools for CX research" by our co-founder and CEO Lukas Rintelen
If you want to learn more about the specific benefits of AI in CX research, we recommend this guest post by our co-founder Lukas Rintelen for marktforschung.de:
https://www.tucan.ai/de/blog/automatisierung-in-vollem-gange-diese-neuen-ki-tools-revolutionieren-die-cx-forschung/
You want to test Tucan.ai for your Company?
Book a free consultation call!
Improving qualitative research with NLP
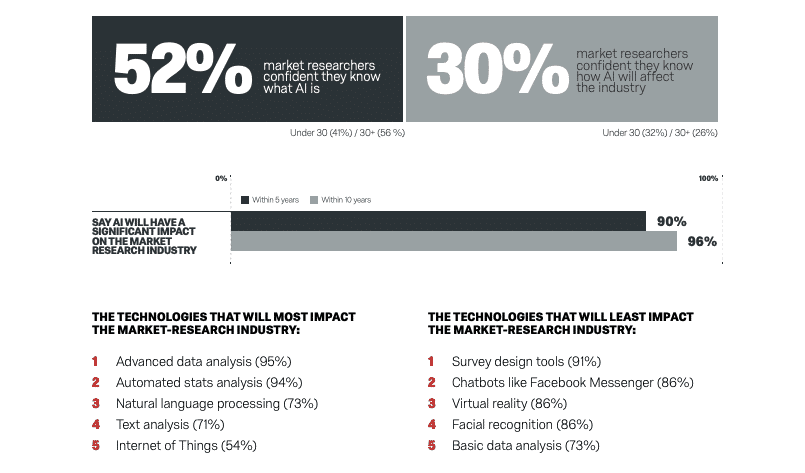
According to a survey conducted by Qualtrics last year, over 50 percent of decision-makers in market research are convinced they know what AI is in concrete terms. Just about all of them assume that it will have a very big impact on the development of the industry in the coming years.
Moreover, trend researchers at an SAP subsidiary focused on experience management predict that at the latest in five years, at least 25 percent of all surveys will be conducted with the help of digital assistants.
Since the release and spread of ChatGPT and other useful solutions based on large language models (LLM), it has become clear that NLP is rapidly gaining in performance and importance. However, OpenAI's prodigy has not mastered everything already possible with the help of algorithms.
New NLP tools for documenting and analysing conversations are currently presented to the public almost daily. Properly applied, AI can positively impact not only how we communicate with machines, but also the way we humans work, research and interact with each other. Thanks to rapid innovation over the past years and months, NLP-based software can now also be used to optimise qualitative research effectively.

Fundamental methods of NLP
NLP methods and systems for speech recognition and conversational intelligence all have clear strengths and weaknesses, but if they are applied in a targeted, controlled and combined manner, they can deliver a great deal of added value.
The fastest growing area is automatic speech recognition (ASR) which converts spoken words into text. These systems work very precisely and are therefore ideal for tasks such as speaker diarisation, logging and transcription. However, when it comes to recognising multiple speakers in noisy environments as well as accents and dialects, some of these solutions still have their difficulties.
Another innovative NLP element are systems for natural language understanding (NLU), one of the areas in which Tucan.ai is specialising. The technology goes beyond transcribing words and tries to determine the meaning behind them. NLU is perfectly suited for sentiment analysis, encoding, and intention recognition.
Finally, there are conversational AI systems that allow programs to have an informative conversation with a human. Virtual assistants can automatically collect data, generate speech and give personalised answers, but usually still find it difficult to correctly classify subtle forms of speech such as idioms or sarcasm.
You want to test Tucan.ai for your Company?
Book a free consultation call!
Benefits of NLP for researchers
Firstly, if developed and applied adequately, NLP can help reduce analysts' personal biases. Whenever a person perceives something, the content is filtered through subjective experiences and opinions before they can understand it, which naturally introduces a certain kind of bias. A typical countermeasure is to have two analysts working on the same data set, bit this usually takes twice as long and costs much more.
NLP tools are now being increasingly applied by researchers to process, encode and extract findings from interviews and focus groups. One main advantage is the ability to quickly and accurately transcribe large amounts of spoken data and collect free-text data that would else be overlooked.
NLP tools can also be used to analyse transcripts and identify key themes, statements and patterns that are difficult to detect through manual analysis. They help us identify specific nuances of speech, such as tone of voice, intonation and nonverbal cues.
In addition, the automated nature of these AI-powered applications allows us to analyse larger data sets, leading to robuster results in less time. Automating manual processes enables researchers to reallocate certain resources, which makes many of these tools very cost-effective.
Uses cases in qualitative research
Many leading market research institutes and companies are already making extensive use of NLP. Industry leaders such as GfK, Kantar, Ipsos and GIM apply or offer automatic speech recognition and text analysis tools to transcribe and encode language data to better capture and classify evidence. Continue reading for the most popular and important use cases of NLP in qualitative research.
Data collection and procession
Automated data capture involves reading text and recording, transcribing and summarising conversations. With the help of AI, these tasks can not only be outsourced and accelerated, but also made more accurate, objective and transparent. For example, some tools are able to produce literate (interjections), corrected (grammar) and abstract transcripts as needed, helping to scale interviews and focus groups more easily.
Text analysis
Text analysis and topic recognition are effective and established methods for gaining reliable insights from larger text datasets. IBM estimates, for instance, that about 80 percent of data worldwide is unstructured and consequently unusable. Text analysis uses linguistic and machine learning techniques to structure the information content of text datasets. It builds on similar methods as quantitative text mining, in addition to modelling, however, the goal is to uncover specific patterns and trends.
Topic recognition
Topic modelling is an unsupervised technique that uses AI to tag text clusters and group them with topics. It can be thought of as similar to keyword tagging, which is the extraction and tabulation of relevant words from a text, except that it is applied to topics and associated clusters of information. NLP models can also compare the data they have been provided with - like the results of a study - with similar resources. In this way, inconsistencies can be identified and "gaps filled" as the AI "knows the context" of other data pools.
Sentence embedding
Probably the most effective application case of NLP in qualitative research to date is AI-assisted sentence embedding. It involves the assignment of words to matching or meaningful opinions, essentially facilitating the processing of large amounts of data and automated extraction of the most important statements from qualitative interviews.
Keyword recognition
Keyword extraction, or recognition, is an analysis technique that automatically extracts the most frequently used and important words and phrases from a text. It's highly useful for automatically summarising content and better understanding the main topics discussed.
Sentiment analysis
Sentiment analysis aims at identifying the intentions and opinions behind the collected data. While text analysis makes sense the data set, sentiment analysis reveals the underlying emotions expressed through a statement or in a conversation. It reduces subjective feelings to abstract but processable representations. As with any data analysis, however, some nuances get of course lost along the way.
You want to test Tucan.ai for your Company?
Book a free consultation call!
More dynamic and authentic insights
Not only can with the help NLP additional and better qualitative insights be gained, interviews and analyses can also be made much more context-sensitive - for example, because interviewers and moderators follow a script that is continuously adapted by a computer.
NLP offers a multitude of new possibilities for optimising research processes and getting a deeper, more dynamic and authentic understanding of collected data. We will likely soon see much more conversational surveys where follow-up and in-depth questions are asked in real time.
That much is clear: AI is about to revolutionise qualitative research. It is not (yet) able to mimic the deep, explorative abilities of humans. However, we have undoubtedly reached a point at which some programmes can execute certain tasks much faster, cheaper and more reliably than humans.

Automation in full swing: These new AI tools revolutionise CX research
In our rapidly digitally transforming information age, it is becoming more and more difficult to deliver compelling and engaging customer experiences. Market leaders in virtually every industry are now putting personalisation at the heart of their business strategy.
For example, Rodney McMullen, CEO of Kroger, recently described seamlessness and personalisation as two very central areas in which the retail group is now primarily investing. Similarly, market leaders in the apparel (e.g. Nike), restaurant (e.g. Starbucks), banking (e.g. JPMorgan Chase) and home improvement (e.g. Home Depot) industries have all said in the past year that they are now strategically focusing on seamless, personalised omnichannel experiences.
Surveys show that customers who have had positive experiences with brands spend more on average and are more loyal in the long term. According to a study by Deloitte, they are willing to pay up to 140 percent more if they have had a positive experience with a brand.
Plus, we know that consumers of generations Y and Z predominantly prioritise brand experiences over products. That doesn't necessarily mean they just want to go on holiday instead of spending their money on trendy sneakers: McKinsey documents a resurgence in demand for "real" shopping experiences.
Now the question is: What contribution can AI and ML make to optimising customer experiences, user retention and conversions?
Let's first take a look at the current situation in market research in general before we go into more detail on how and for what machine and deep learning technologies can be used in CX research and which tools and providers are currently enjoying particular popularity.
Use of AI grows rapidly across industries
We are now at a point where competitive advantage is increasingly derived from the ability to meticulously capture, analyse and process large volumes of customer data, and effectively use AI/ML to better understand, design and manage customer journeys.
To create impactful experiences, companies need ongoing insights based on a comprehensive, in-depth understanding of their customers. In digitalised, fast-moving markets, there is a need for innovative, agile and semi-automated CX research that combines diverse analytical methods and makes targeted use of AI/ML. Especially on this side of the Atlantic, however, the road ahead is still a rocky one for many.
In a variety of other industries, the use of AI/ML has already grown exponentially. An O'Reilly report from 2021 shows that IT and electronics tops the rankings (17%), followed by financial services (15%), healthcare (9%) and education (8%).
However, the fact that AI/ML still play a relatively small role in market research in no way diminishes the industry's expectations:
According to a survey conducted by Qualtrics this year, a good half of the market research decision-makers surveyed are convinced that they know exactly what AI is; almost all of them assume that AI/ML will have a significant impact on the development of market research over the next ten years; and around 30 per cent are confident that they can adequately anticipate the impact. Trend researchers at the SAP subsidiary specialising in experience management also predict that in five years at the latest, at least 25 percent of all surveys will be conducted using digital assistants.
You want to test Tucan.ai for your Company?
Book a free consultation call!
Advantages for market and CX research
AI/ML tools help companies gain a better understanding of customer behaviour, what problems they have and how they react to certain offers. They make it possible to collect, analyse and interpret data more quickly and accurately.
At the latest since the publication of the language model ChatGPT developed by OpenAI a few weeks ago, computer linguistic methods for Natural Language Processing in particular have been the talk of the town. With NLP, text and speech data can be systematically collected and analysed to find out, for example, how customers behave and react to stimuli. Complex data patterns can then be recognised and interpreted better and better thanks to algorithms.
Long story short: AI/ML offers numerous opportunities to optimise collection and analysis processes. Despite the challenges of developing flexible models that can work with unpredictable language, the usefulness of using AI in market and CX research is unmatched. The following is an overview of the key benefits:
1. Saving resources
Arguably the biggest added value of AI/ML is the time it helps save. Effective automation can reduce the duration of a project from months to weeks or even days. As a result, analysts and marketers can spend more time evaluating, interpreting and telling the story behind the data than calculating generalisable numbers or trying to make sense of relevant wordings. AI/ML also allows companies to redeploy human resources elsewhere and reduce costs for external providers.
2. Higher data quality
There are many challenges that companies and brands face today when it comes to efficient access, use and exploitation of data. According to the latest Dell Digital Transformation Index (2020), data overload and "inability to gain insights from data" are the biggest barriers to successful digital transformation.
Also a major challenge in the area of data analytics are so-called data silos. This refers to data stores that can be accessed little or not at all, e.g. because they are poorly prepared or have been isolated in individual departments.
Although AI/ML are not a miracle cure for such silos, they offer companies tools to gain much deeper insights. Higher quality data usually contributes to much better results. After all, because AI/ML tools generally make it easier to analyse qualitative data by automating collection, processing and linking processes, we can now collect a lot more of it.
In addition, AI systems are now able to identify themes, correlations and subtle nuances in and between individual statements that are often overlooked and passed over in manual documentation. The free-text data obtained enables additional, usually deeper insights.

Use cases in CX research
In the following, I would like to present the most common use cases of AI/ML in customer experience analytics and a few innovative companies leading the way. The most widely used methods and tools include clustering and categorisation algorithms, text and sentiment analysis, and predictive models.
An absolute must-know for every market researcher and CX researcher is definitely Kantar Marketplace, launched in mid-2019. The automated platform, which is available in 70 countries, delivers decision-relevant insights in no time, whether companies need feedback on an idea, are developing a new product or launching a campaign. With Marketplace, Kantar offers an innovative toolbox that enables researchers, professionals and agencies to gain deeper insights through automation and make data-driven decisions faster.
1. Automatic collection
A promising way to drive CX enhancement, friction reduction and cost reduction go hand in hand is automation through so-called bots. In the new year, they are arguably the strongest and most visible trend towards AI/ML in market and customer research.
In response to the Corona pandemic, demand for AI assistants in the industry has skyrocketed. AI/ML-based assistance tools such as those from IBM, Zaoin and boost.ai help CX professionals automate and optimise analytics processes and customer relationships. Virtual agents, for example, pre-select customer queries and automatically answer routine queries. Using scripted rules, AI and ML, they generate automated responses, continuously learn new answers to basic questions through integrations with backend systems, and can handle a much larger volume of queries than humans.
2. Clustering algorithms
Speaking of big data: Most companies already capture a lot of customer interactions in their CRM systems. However, much of this data needs to be properly structured before it can actually provide insights. Using information about customer interactions, AI systems are now being trained to replicate the work of a customer service representative. Leading providers such as Qualtrics use clustering algorithms to do this.
Clustering is a technique that can automatically classify thousands of lines of unstructured conversations. In this way, a company's customer service data can be retrieved for analysis in seconds and successful responses, frequencies, urgencies, etc. can be shown. Deep learning algorithms are used to automatically cluster data and elicit frequently asked customer questions and assess the extent to which support can be automated.
3. Automatic summarisation
AI also comes in handy for summarising videos and audios in CX research. Through the targeted use of NLP, we can now automatically transcribe and summarise gigantic amounts of video and audio feedback. Important information is thus captured more quickly and resources can be focused on more important tasks.
The German software company Tucan.ai, for example, offers AI-generated conversation summaries in addition to automatic recording, transcription and coding. This is particularly useful for those who want to analyse large amounts of data from interviews, group conversations, etc. and save time by not having to document or categorise them manually.
4. Categorisation and coding
The biggest challenge in analysing call data is usually the time and cost associated with manually coding and categorising collected data. Again, Tucan.ai's NLP-based SaaS platform can provide a quick remedy. It is therefore already being used in this country by well-known industry players such as Kantar and GIM.
The Berlin-based deep-tech start-up has developed an in-house AI system that can, among other things, automatically code and categorise conversation data. Large amounts of data are thus processed faster and more precisely, allowing targeted and comprehensive analyses to be carried out and deeper insights into views and customer needs to be gained. This in turn enables key resources to be reallocated, recurring concerns to be responded to more quickly, and products and services to be adapted accordingly.
5. Predictive models
Link AI is an AI platform that predicts the performance of a digital advertisement in the market. It has been trained with Link, the world's largest advertising database, which includes over 230,000 survey-based tests with 30 million real human interactions. Link AI breaks down each ad into individual images and further decomposes the content into images, audio, speech, objects, colours, text as well as other attributes. Then, using AI video processors, the machine extracts up to 20,000 features from the video file, feeds them into machine learning models and finally predicts the score of the ad based on metrics for "creative effectiveness".
AI-driven predictive approaches also become increasingly popular for surveys. For example, SurveyMonkey uses AI-powered tools to help companies design and analyse surveys, predict completion rates and automate data analysis. The tool is widely used for customer and employee surveys, market research and other forms of feedback collection.
6. Audience Journey Tracking
Another area where computer learning is currently on the rise is audience journey mapping. With the help of AI, it’s now possible to precisely document a wide range of customer interactions with a brand or company from start to finish. This way, you can determine more precisely when customers experience friction losses or where exactly they deviate from the interaction process.
Well-known examples of AI-supported audience journey mapping include the web tools HotJar, Appier and Fullstory. They can be used, for example, to specifically observe individual website sessions of those customers who do not complete a purchase. This allows qualitative insights to be gained that are often not properly captured in statistical evaluations of large data sets.
For audience journey tracking, the smart software Knotch is becoming increasingly popular. It can bring together different interactions that customers have with companies over time and show those paths that bring the most conversions. Instead of analysing isolated campaigns that compete with each other for revenue share, Knotch accurately determines exactly how much impact each digital interaction or content had on sales.
7. Automatic sentiment analysis
Sentiment analysis uses AI and ML to determine the emotions expressed in words. It follows a predetermined metric to understand how positive, neutral or negative a statement or text sounds. AI systems can "pre-analyse" millions of comments on social media, rating portals and online surveys.
The innovative use of sentiment analysis outside of commercial market and customer analysis was demonstrated by the AI-powered social media analysis of En Marche in the course of the 2020 Senate elections in France: Emmanuel Macron's party reportedly used NLP and sentiment analysis to gain deep insights into voters' preferences expressed online on certain topics.
In CX research, it comes handy, in particular, for achieving the following goals:
-
Improving marketing campaigns: monitoring sentiments, understanding emotional responses to specific messages and better assessment of competitors' reception.
-
Prioritisation in customer service: prioritise tickets faster, optimise queues through automation, enables faster, more specific responses to feedback
-
Detailed understanding of customers' perceptions of products and brands
-
Trend analysis, forecasting: e.g. reactions to new interfaces or features
-
Churn prediction: e.g. capture negative sentiment online in real time
Sentiment analysis, often called opinion mining in English, is a sub-field of NLP. At its core, it automatically captures and categorises large numbers of individually expressed opinions, transforming unstructured data into actionable information. A real specialist for automated sentiment and emotion analyses, which Qualtrics Marketplace, among others, relies on, is, for example, the British start-up Adoreboard with its "Emotion AI Platform".
From competitive advantage to necessity
Please note that this article does not claim to be exhaustive and merely aims to provide an initial overview of the myriad new players, tools and opportunities that have recently emerged in the CX segment thanks to rapid advances in AI/ML. There are numerous other great applications out there that deserve your attention as well. If you know of any that you would like to bring to our attention, we would of course love to hear from you.
Nevertheless, this article shows very clearly that the targeted use of AI/ML tools is no longer merely a promising competitive advantage, but has become a basic prerequisite for participating in the competition for attention and loyalty. Due to the increasing digitalisation of our society and the ever-growing competition in the online sector, it has become much more difficult to clearly stand out from competitors.
Those who can process large amounts of data, analyse metadata and recognise patterns in a short time gain deeper insights into the thoughts and behaviours of customers. Those companies that do not yet have this capability should start testing innovative solutions as soon as possible. Otherwise, they will inevitably fall behind in the coming years.
You want to test Tucan.ai for your Company?
Book a free consultation call!

Top 5 German Podcasts for Market Researchers
If you're fluent in German or are looking to improve your language skills, there are many excellent German-language podcasts out there that cover a range of topics related to market research and opinion mining. Here are the five most important ones that you won't want to miss:
1. Marktforschung aktuell
Hosted by market research expert Dr. Sebastian Kühn, "Marktforschung aktuell" (or "Market Research Up-to-Date") is a weekly podcast that covers a variety of topics related to the field. In each episode, Kühn interviews leading industry experts and discusses the latest trends and developments in market research.
According to Kühn, one of the goals of the podcast is to make market research more accessible to a wider audience. "Many people don't really know what market research is all about, or they have a distorted image of it," he says. "With 'Marktforschung aktuell,' we want to shed light on the various aspects of market research and show how interesting and diverse the field really is."
2. Marktforschung pur!
"Marktforschung pur!" (or "Pure Market Research") is another great podcast for anyone interested in the field. Hosted by market research professionals Anna Schütz and Christin Beyhl, the podcast covers a wide range of topics, from the latest industry trends and techniques to practical tips for market researchers.
In an interview with the hosts, Schütz emphasised the importance of staying up-to-date with latest developments in the field. "As market researchers, it's essential to constantly learn and evolve to stay relevant and provide valuable insights to our clients," she says. "That's why we started 'Marktforschung pur!' - to share our knowledge and experience with others in the industry."
3. Meinungsforschung im Fokus
"Meinungsforschung im Fokus" (or "Opinion Research in Focus") is a podcast that focuses specifically on the field of opinion mining. Hosted by market research professionals Marcel Büchi and Marc Schneider, the podcast covers a range of topics, including the latest techniques and tools for gathering and analyzing public opinion data.
In an interview with the hosts, Büchi emphasized the importance of understanding public opinion in today's fast-paced, digital world. "With the proliferation of social media and other online platforms, it's more important than ever to track and understand public opinion," he says. "That's what 'Meinungsforschung im Fokus' is all about - helping market researchers and other professionals stay on top of the latest trends and techniques in opinion mining."
4. Marktforschung 2.0
"Marktforschung 2.0" (or "Market Research 2.0") is a podcast that covers the latest trends and developments in the field, with a particular focus on the role of technology and digital tools. Hosted by market research professionals Martin Fischer and Thomas Häussler, the podcast features interviews with industry experts and discussions on many topics, including data analytics, customer experience, and market research software.
Fischer emphasizes the importance of staying on top of technological advancements in the field. "As market researchers, it's essential to keep up with the latest technologies and how they can be used to gather and analyze data," he says. "That's what 'Marktforschung 2.0' is all about - helping professionals stay up-to-date and succeed in an increasingly digital world."
5. Die Marktforscher
"Die Marktforscher" (or "The Market Researchers") is a podcast that offers a broad overview of the market research industry. Hosted by market research professionals Julia König and Michael Schmieder, the podcast covers a range of topics, including industry trends, best practices, and case studies.
In an interview with the hosts, König emphasized the importance of staying current in the field. "As market researchers, it's essential to stay on top of the latest trends and techniques in order to provide valuable insights to our clients," she says. "That's what 'Die Marktforscher' is all about - helping professionals stay up-to-date and succeed in their careers."
These are just a few of the many excellent German-language podcasts out there for market researchers and opinion miners. Whether you're looking to learn about the latest industry trends, improve your skills, or simply stay up-to-date, these podcasts are a great resource to add to your list.