Language models can perform a variety of tasks, including writing essays, summarising articles, answering questions, creating captions and even composing music. But not all of them are created equal. There are different kinds of language models, each with its own strengths and weaknesses. In this blogpost, we will explore the three major types which have emerged as dominant, and we will discuss why and how they can be extremely beneficial to us.
Large language models
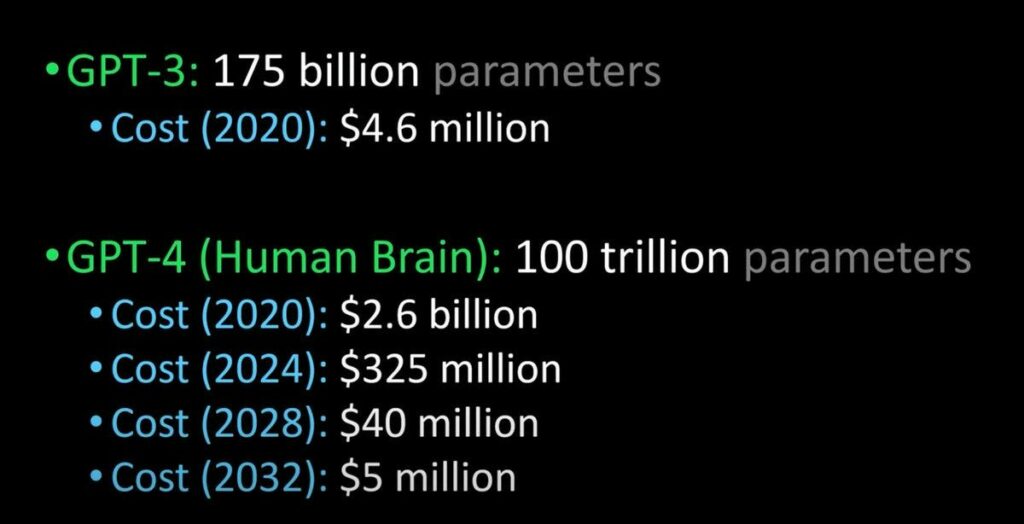
Large language models are the behemoths of the language modeling world. They are trained on massive amounts of text data, sometimes billions of words, from various sources such as books, websites, social media, and news articles. They use deep neural networks with hundreds of layers and billions or trillions of parameters to learn the statistical patterns of natural language.
Some examples of large language models are GPT-3 and -4, BERT, and T5. These models can generate coherent and diverse texts on almost any topic, given a suitable prompt. They are also able to perform multiple tasks without any further training, by using few-shot prompting techniques. GPT can write movie reviews, solve math problems, take college-level exams, and even identify the intended meaning of a word.
Large language models are impressive, but they also have their limitations. Firstly, they require plenty of computational resources to train and run, which makes them expensive and inaccessible to many users. Secondly, large language models consume a lot of energy, which raises environmental concerns. Lastly, they may inherit biases and errors from their training data, which easily leads to harmful or misleading outputsl
Fine-tuned language models
Fine-tuned language models are the specialists of the language modelling world. They are trained on a specific task or domain, using a smaller amount of data that is relevant to the task or domain. They use pre-trained large language models as a starting point and then fine-tune them on the task or domain data.
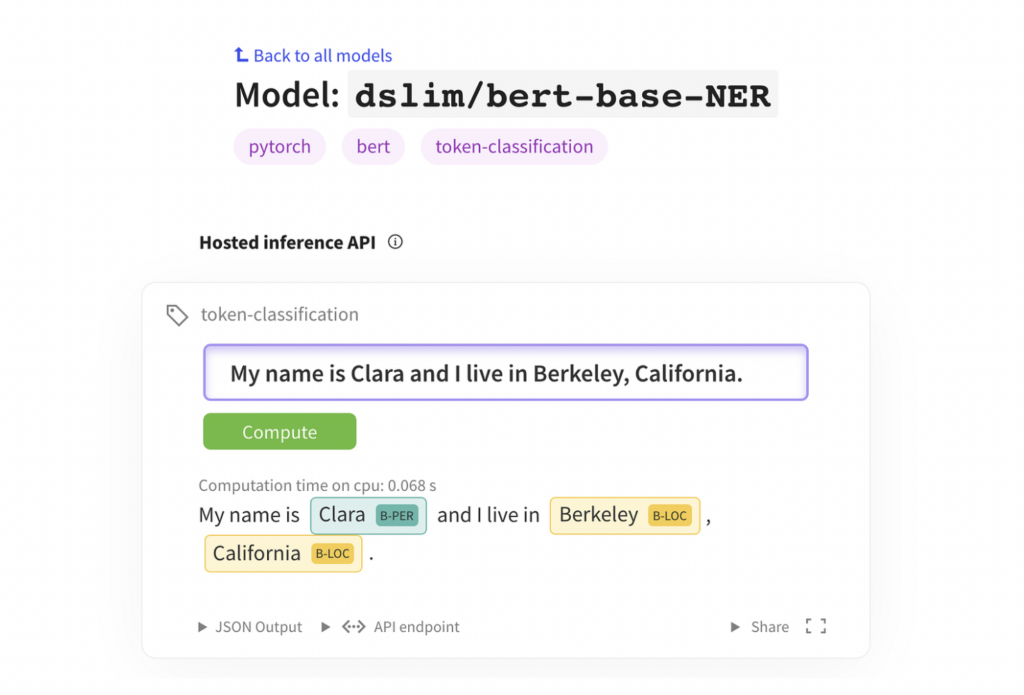
Some examples of fine-tuned language models are OpenAI Codex, GPT-3 Ada, and BERT-base-NER. These models can perform tasks that require more domain knowledge or accuracy than large language models. For example, OpenAI Codex can generate computer code from natural language descriptions2, GPT-3 Ada can write high-quality medical texts3, and BERT-base-NER can recognise named entities in text.
Fine-tuned language models are powerful, but they also have some drawbacks. They require more data and expertise to train than large language models. They may also overfit to the task or domain data and loose some of the generalisation ability of large language models. Furthermore, they may still suffer from some of the biases and errors of large language models.
Edge language models
Edge language models are the lightweights of the language modeling world. They are designed to run on devices with limited computational resources like smartphones, tablets or smartwatches. Edge language models use smaller neural networks with fewer layers and parameters to generate natural language text.
The most prominent examples are TinyBERT, MobileBERT and DistilGPT-2. These models can perform tasks that require fast and local processing of natural text. For example, TinyBERT is able to answer questions on mobile devices, while MobileBERT can create captions for images on tablets and DistilGPT-2 has the skill of writing short texts on smartwatches.
Edge language models are definitely convenient, but they are also challenging, as optimising their size and speed without compromising their quality requires more engineering effort. Furthermore, they lag behind the state-of-the-art performance of large or fine-tuned language models on some other tasks.
Why language models matter
Language models matter because they enable us to communicate with computers in natural ways. They also empower us to access information more easily and efficiently. And they inspire us to create new forms of art and expression.
Imagine you are planning a trip to Paris and you want to find the best hotel, the cheapest flight, and the most interesting attractions. You could spend hours browsing through different websites, comparing prices, reading reviews, and making reservations. Or you ask a language model to do all that for you in minutes.
Language models are not only useful for travellers, but for anyone who needs to communicate with others or access information. They can help us research stories and write stories, but also learn new languages.
However, they do also pose some risks that we need to address. They may easily generate false or harmful information that can misinform or manipulate us, or they may amplify existing social inequalities or create new ones by excluding or discriminating against certain groups of people.
We need to be well-aware of the capabilities and limitations of different types of language models in order to use them responsibly and ethically. And we need to engage in continuous constructive collaboration and dialogue with researchers, developers, policymakers as well as users of language models.