Von Daten zu Insights: KI-Geheimnisse für Marktforschungs-Profis
In einer Zeit, in der Daten das A und O sind, revolutioniert die Integration von künstlicher Intelligenz (KI) in die Marktforschung die Art und Weise, wie wir Erkenntnisse gewinnen und interpretieren. In seinem letzten Webinar "Von Daten zu Insights: KI-Geheimnisse für Marktforschungs-Profis", bot Florian Polak, Mitgründer von Tucan.ai, einen tiefen Einblick in die praktischen Anwendungen von KI in der Marktforschung. Dieser Blogbeitrag bietet eine ausführliche Zusammenfassung des Webinars auf martforschung.de und beleuchtet die Vorteile, die KI-Lösungen für die Branche bringen können.
"Wir wissen, wie wichtig die Transparenz und Zuverlässigkeit der von unserer KI gelieferten Ergebnisse ist."

Interview Marktforschung.de mit Florian Polak
Geschäftsführer, Tucan.ai GmbH
Edit Content
Edit Content
– Tucan.ai ist ein junges Unternehmen aus Berlin, spezialisiert auf die Extraktion relevanter Informationen aus Text-, Audio- und Videodateien für Marktforschungszwecke.KI-Systeme und Anwendungen:
– Es wurde ein Überblick über KI-Systeme und deren Anwendung in der Marktforschung gegeben, inklusive Tipps und Tricks für den effizienten Einsatz.
– Tucan.ai bietet Produkte an, die es ermöglichen, KI-Technologien zur Effizienzsteigerung und zur Überholung der Konkurrenz einzusetzen.
Probleme und Lösungen bei KI-Systemen:
– Diskussion über gängige Probleme bei der Nutzung von KI-Systemen, insbesondere das Phänomen der “Halluzination” von KI, ungenaue oder oberflächliche Antworten und Datenschutzbedenken.
– Tucan.ai nutzt spezielle Technologien und Ansätze, um präzise und relevante Ergebnisse zu liefern und gleichzeitig Datenschutz und Sicherheit zu gewährleisten.
Anwendungsbereiche und Funktionen:
– Tucan.ai’s Software ermöglicht die Auswertung von Online-Communities, qualitative Kodierung von Interviews oder Gruppenstudien und quantitative Auswertung von Textdaten.
– Die Software unterstützt verschiedene Datenformate und bietet eine hohe Verarbeitungsgeschwindigkeit und Genauigkeit.
Datenschutz und Sicherheit:
– Tucan.ai garantiert, dass Daten ausschließlich in Deutschland verarbeitet werden und bietet verschiedene Kooperationsmodelle an, einschließlich On-Premise-Lösungen.
Preismodelle:
– Tucan.ai bietet flexible Preismodelle an, die auf Projektbasis oder als jährliche Pauschale gestaltet werden können, abhängig von den Bedürfnissen des Kunden.
Fragen und Antworten:
– Im Webinar wurden verschiedene Fragen der Teilnehmer beantwortet, unter anderem zur Verarbeitung von Dialekten, der Möglichkeit, Audiodateien zu testen, und zur Verarbeitung und Analyse von demografischen Daten in Verbindung mit offenen Antworten.
Abschluss:
– Das Webinar endete mit dem Angebot, bei weiteren Fragen Kontakt aufzunehmen und der Ankündigung, dass eine Zusammenfassung des Webinars zur Verfügung gestellt wird.
Edit Content
Schönen guten Tag. Hallo. Florian Polak ist mein Name hier von Tucan.ai. Willkommen bei unserem Webinar zur Woche der Marktforschung von Tucan.ai. Ich glaube, wir können schon anfangen. Ich werde Ihnen ganz kurz nur den Ablauf erklären. Ich werde Ihnen einen Überblick geben zu verschiedenen Themen im Rahmen der CI Forschung. Natürlich. Ähm, wir werden im Anschluss. Ich glaube, ich schätze mal, dass ich so 20 30 Minuten maximal brauchen werde. Wenn werden im Anschluss auch eine Fragerunde machen. Haben Sie in der Zwischenzeit Fragen? Bitte schreiben Sie die in unseren Chat einfach hinein und am Schluss, im Anschluss des Webinars, werde ich natürlich alle Fragen beantworten, die Sie im Chat gestellt haben.Florian Polak: 00:00:42,400 –> 00:01:21,640
Wunderbar. Dann würde ich ganz kurz anfangen. Vielleicht ganz kurz zu mir. Florian Polak hier. Ich bin einer der Geschäftsführer von Tucan.ai. Mein Job, abgesehen davon Webinare zu halten, ist es mehr oder weniger eigentlich zu übersetzen, was unsere technische Abteilung alles macht. Wir sind ein junges Unternehmen aus Berlin, die mittlerweile seit fünf Jahren am Markt und haben uns darauf fokussiert, gerade im Bereich Marktforschung relevante Informationen aus einer großen Menge von Text oder auch aus Audio oder Videodateien im Prinzip zu extrahieren. Ich werde Ihnen einen kurzen Überblick jetzt mal geben. Wunderbar, wir fangen auch schon an, was werde ich in diesem Webinar alles machen?Florian Polak: 00:01:22,360 –> 00:01:57,730
Ich werde ein bisschen eingehen auf KI Systeme und Begrifflichkeiten da drin in Ihnen versuchen simpel einen Überblick zu geben. Ohne jetzt zu sehr in die Details hier reinzugehen. Ich werde Ihnen vor allem aber auch ein paar Tipps und Tricks auf den Weg geben, worauf Sie vielleicht beim Arbeiten mit KI auch achten sollten. Und ich werde Ihnen natürlich auch zeigen, was wir grundsätzlich für Produkte anbieten und wie Sie entweder mit uns oder auch das selber im Prinzip aufbauen können, dass Sie KI Technologien bei Ihnen einsetzen und im Prinzip damit natürlich sehr, sehr effizient ihre Konkurrenz im Prinzip abhängen können.
Florian Polak: 00:01:59,660 –> 00:02:29,660
Was ist auf der Agenda? Hier eine kurze Vorstellungsrunde zu uns machen, was wir so machen, was wir grundsätzlich anbieten. Ich werde dann vor allem aber auch einen Fokus darauf legen, was für Probleme mit KI Systemen eigentlich sind, sondern was man da eigentlich ein bisschen achten sollte. Ich werde ein bisschen darauf eingehen, wie so grundsätzlich der Markt aktuell agiert und was gut daran ist und was vielleicht nicht so gut daran ist. Dann gebe ich Ihnen natürlich auch einen Überblick über unsere Software und werde Ihnen auch verraten, im Prinzip, was hinter unserem System steckt, wie wir das Ganze im Prinzip aufgebaut haben.
Florian Polak: 00:02:30,260 –> 00:03:08,210
Um Ihnen einfach nochmal einen Überblick zu geben, warum unser System in diesem Fall sehr gut geeignet ist für die Marktforschung. Dann natürlich zu guter Letzt noch ein kleines Thema über das Thema Datenschutz natürlich. Und Sicherheit ist sehr wichtig, gerade in der Auswertung von Studien und natürlich, was wir grundsätzlich für Preispakete haben, damit Sie den Überblick haben. Zu guter Letzt eine Fragerunde, wo sich alle Ihre Fragen beantworten werde, die Sie in diesem Chat stellen. Dann fangen wir auch schon kurz mal an, wir würden grundsätzlich in 2019 gegründet, sind ein Kleinunternehmen aus Berlin, haben mittlerweile 20 Mitarbeiter, ein Großteil davon natürlich in der Technikabteilung.
Florian Polak: 00:03:09,050 –> 00:03:51,800
Haben da eigene KI Spezialisten, die sich in den letzten vier, fünf Jahren eigentlich damit beschäftigt haben, solche Algorithmen und aber auch natürlich Infrastruktur dafür aufzubauen, mit dem Fokus immer mehr einer Analyse von Gesprächen, aber auch Texten gut hinbekommen. Wir haben uns fokussiert, Da wir ja als deutsches Unternehmen mit auch sehr öffentlichen oder sehr großen Unternehmen zusammenarbeiten, haben wir uns darauf fokussiert, eben auf sensible Informationen zu verarbeiten mit dem entsprechenden Sicherheits und Datenschutzstandards, die damit einhergehen, und haben hier aber auch in der Marktforschung mittlerweile auch recht große Kunden. Was kann man mit unserer Software machen? Ganz grob gesagt sind es drei Bereiche.
Florian Polak: 00:03:52,010 –> 00:04:38,180
Das eine ist im Prinzip Online Communities auswerten, das heißt wirklich Fragen an große Datenmenge zu stellen. Dann natürlich die qualitative Kodierung von Kern, von Interviews oder Gruppenstudien und natürlich auch vor allem bei frei Textnennungen, also Textdaten, im Prinzip Excel oder Textdateien quantitativ im Prinzip auszuwerten, wann immer Sie eine Freitagsnennung haben, das möglich auf einen einzelnen Code zu verdichten und dann im Prinzip das Ganze auszuwerten. Ähm, ja, grundsätzlich unsere. Wir haben einige Kunden hier in Deutschland mittlerweile die größten, die wir haben, ist einerseits die deutsche Bundeswehr, aber auch im Automobilsektor. Recht viel ist mittlerweile mit Porsche und Mercedes Benz und im öffentlichen Bereich vor allem auch natürlich Landtag.
Florian Polak: 00:04:38,180 –> 00:05:18,290
Mecklenburg Vorpommern ist einer unserer größten Kunden hier. Grundsätzlich die drei Bereiche. Was kann man da genau machen? Im qualitativen Forschungsbereich geht es vor allem darum, Interviews oder Gruppendiskussionen im Prinzip zu einerseits zu transkribieren, da damit haben wir ursprünglich mal angefangen haben eigene Spracherkennungsalgorithmen aufgebaut, wie Sie es vielleicht hören. Ich bin Österreicher, der auch verschiedene. Im Prinzip Akzente und Dialekte kann unser Algorithmus ganz gut verstehen. Das Ganze wird in Text gebracht und dann geht es darum, im Prinzip anhand eines Leitfadens oder Ihrer Fragen im Prinzip relevante Antworten zu extrahieren und zusammenzufassen und wieder zu verdichten. Das selbe Thema dann auch in der quantitativen Forschung.
Florian Polak: 00:05:18,290 –> 00:05:56,180
Hier geht es vor allem darum, dass man wirklich große Mengen von Antworten hat, also beispielsweise Kundenservice ist ein klassischer Fall, wo dann sehr, sehr viele Antworten in alle Richtungen natürlich gehen, wo man diese Textendungen dann verdichtet, im Prinzip mit einem entweder bestehenden Codeplan oder aber auch die KI tatsächlich selber Code Pläne finden zu lassen. Im Durchschnitt braucht es unser System für so circa 1000 Freitagsnennungen unter zwei Minuten. Das geht also relativ fix. Das Ganze dann natürlich die Community so auswerten. Da geht es dann darum, dass wir viele, viele verschiedene Daten haben. Also sie können diese Daten entweder bei Excel hochladen oder aber auch per API Schnittstelle mit unserem System.
Florian Polak: 00:05:56,720 –> 00:06:38,450
Und dann können Sie Fragen im Prinzip an diese Datenmengen stellen, um dann relevante Ergebnisse im Prinzip zu extrahieren. Mehr dazu ein bisschen später. Verschiedenste Formate funktionieren bei uns Audio Videodateien, Excel wie schon erwähnt bzw. Maschinen lesbarer Text kann angeschlossen werden. Das Ganze natürlich auch eben als Schnittstelle mit Ihrem System. Wir haben ein paar Garantien, die wir Ihnen geben. Das eine Thema ist Anti Halluzination, da komme ich gleich nachher noch kurz darauf zu sprechen, was das eigentlich ist und wie man das dagegenstellen kann, dass wir im Prinzip ihnen helfen, eigentlich, dass unsere KI die relevanten Ergebnisse aus den Textmengen oder Datenmengen auch extrahiert.
Florian Polak: 00:06:38,900 –> 00:07:17,930
Dann garantieren wir Ihnen auch, dass die Daten ausschließlich in Deutschland verarbeitet werden. Da gibt es mehrere Varianten zusammenzuarbeiten. Wir haben unsere Server grundsätzlich Berner Anbieter namens Hetzner. Das heißt, wenn Sie mit unserer Cloud zusammenarbeiten, wird das ausschließlich auf diesem Server verarbeitet. Oder wir können sogar unser gesamtes System bei Ihnen auf dem Server installieren. Haben wir bei sehr großen Kunden schon auch gemacht. Einfach damit die Daten ihr System einfach gar nicht mehr verlassen. Dann natürlich, dass die Daten von unseren Kunden ausschließlich ihnen zur Verfügung stellen. Also sowohl die Extrakte im Prinzip, die Sie mit unserer Query rausbekommen, als natürlich die Daten, die Sie bei uns hochladen.
Florian Polak: 00:07:18,170 –> 00:07:58,670
Wir nutzen Ihre Daten nicht zu Trainingszwecken, außer natürlich, das ist gewünscht. Also wir können auch im Prinzip speziell für Ihren Fall dann natürlich auch ein eigenes Datentraining durchführen. Und last but not least, wenn Sie sehr, sehr große Datenmengen haben Sie haben bei uns keine Begrenzung an hochgeladenen Daten, das heißt, Sie können da wirklich rein jagen, was auch immer Sie da drinnen haben, weil und kriegen trotzdem ein sehr performantes Ergebnis, werde ich nachher kurz noch mal ein bisschen was dazu sagen, dass Sie auch bei großen Datenmengen tatsächlich relevante Ergebnisse sehr präzise rausbekommen. Gut, dann steige ich auch schon ein mit Problemen grundsätzlich bei Studie Auswertung von Studien mittels KI.
Florian Polak: 00:07:59,570 –> 00:08:39,169
Das Hauptthema ist das Thema Halluzination. Also im Prinzip wirklich, dass die KI Ergebnisse bringt, die eigentlich nicht relevant sind. Um auf die Frage, die sie gestellt haben wir Es gibt da verschiedene Mechanismen, die man entgegenwirken kann. Ich werde nachher kurz ein bisschen was dazu sagen, was das eigentlich ist oder was üblicherweise die. Die Gründe dafür sind dann ein sehr, sehr wichtiges Ergebnis. Ich weiß nicht. Ich nehme mal an, dass viele von Ihnen schon mittlerweile mit Start up oder ähnlichen KI Systemen gearbeitet haben. Grundsätzlich gibt es geht es ja auch teilweise jetzt schon ganz gut. Allerdings sind im Regelfall gerade bei großen Datenmengen die Ergebnisse relativ ungenau oder unpräzise und eher oberflächlich.
Florian Polak: 00:08:39,590 –> 00:09:19,370
Dafür gibt es ganz gute Gründe, zu denen ich auch gleich noch ein bisschen was sagen werde. 121 anderes Thema natürlich. Je nachdem, in welchem Anbieter sie arbeiten, werden Daten teilweise zu Trainingszwecken weiterverwendet, weil die Systeme erst im Prinzip im Aufbau sind oder sich ständig weiterentwickeln. Oder die Daten werden natürlich in Anbieter an die USA weiter übermittelt. Als Beispiel wäre da zB IT zu nennen und beispielsweise das ist natürlich ein großes Risiko, weil ihre sensiblen internen Daten dann eventuell in zukünftigen Modellen im Prinzip als Antwort auch rauskommen können, was natürlich nicht in ihrem Interesse ist. Und sie haben sich auch schon ein bisschen was darüber gehört über das Thema Tokens.
Florian Polak: 00:09:19,880 –> 00:10:22,610
Und grundsätzlich trugen sie es in der Art und Weise, wie an solche Komodelle im Regelfall abrechnen oder bzw. wie. Wie viele Informationen auf einmal verarbeitet werden können. Das Man kann sich unter einem Token ungefähr ein Wort vorstellen, Das heißt, wie viele Wörter können von der KI gelesen werden? Da gibt es Limitierungen. Grundsätzlich. Zwar werden diese Kontextwindows im Prinzip also die Art, die Anzahl an Wörtern, die sie einspielen können, zwar immer größer, trotzdem haben sie da immer noch eine Limitierung, die natürlich nicht gewünscht ist. Wenn man große Datenmengen also von einer ganzen Studie beispielsweise auswerten möchte. Und eines der wichtigsten Themen für uns ist im Prinzip Nicht nur die tatsächlichen Ergebnisse der KI sollten angezeigt werden, sondern auch tatsächlich die Originalzitate, also die Originaltext stellen aus den Studien, die nämlich auch relevant sind, um vor allem den Kontext besser zu verstehen, aber auch natürlich, um zu überprüfen, ob die Antwort der KI tatsächlich richtig ist oder ob es sich beispielsweise um eine Halluzination handelt.
Florian Polak: 00:10:22,820 –> 00:11:03,950
Das sind so die wichtigsten Themen eigentlich in diesem Bereich. Ich werde mal kurz erzählen, grundsätzlich, was für Technologie sich hinter TTP versteckt. Es handelt sich um etwas, das nennt sich Large Language Model. Es sind verschiedene Arten von Modellen, aber im Prinzip basiert eigentlich alles auf dieselbe Art und Weise. Ist im Prinzip ein Modell, das gemacht wurde, um Sätze zu vervollständigen, basierend auf Wahrscheinlichkeit, das heißt, basierend auf dem Kontext, den Sie als Frage stellen, und dem Kontext, den Sie beispielsweise als Studie in das System hineinspielen. Versucht die ZBD beispielsweise die, den Satz zu vervollständigen, so dass er möglichst akkurat ist.
Florian Polak: 00:11:06,110 –> 00:11:45,920
Man muss sich darunter vorstellen Diese ganzen großen Land Language Modellen wurden mit Milliarden und Milliarden von Daten im Prinzip gefüttert. Das heißt, sie haben Milliarden von Daten im Prinzip gesehen und Sätze gelesen und können dann aufgrund dieser Trainingsdaten im Prinzip Sätze vervollständigen. Das ist im Wesentlichen eigentlich, was die Technologie hinter JPC ist. Das bedeutet natürlich, dass diese Systeme manchmal ist die wahrscheinlichste Antwort die korrekte. Das muss aber nicht immer der Fall sein. Das kann auch passieren, dass das System irgendwo abbiegt, die Frage zum Beispiel falsch versteht oder auch den falschen Kontext hat, um die Antwort im Prinzip zu generieren.
Florian Polak: 00:11:46,100 –> 00:12:25,880
Und dann passiert etwas, was im Umgangssprachlichen mittlerweile Halluzinieren genannt wird. Das ist im Prinzip ein Sammelbegriff für viele verschiedene Probleme. Das ist im Regelfall der Hauptgrund ist darauf, dass die KI im Prinzip. Auf die falschen Daten zurückgreift und dann im Prinzip die falschen Informationen liefert, um die Frage zu beantworten. Aus Nutzerperspektive ist es natürlich Sie stellen eine Frage, wollen eine Antwort haben und das System liefert Ihnen eine völlig falsche Antwort, was objektiv falsch ist und im Prinzip dann unter Halluzinieren zusammengefasst wird. Letztes Thema, was auch sehr, sehr wichtig ist, Wo ich gerade vorhin erwähnt habe, diese Kontextwindows oder auf deutsches Kontextfenster.
Florian Polak: 00:12:25,910 –> 00:13:01,730
Das ist im Prinzip schon ein bisschen ein Markttrends von den großen, laut Language Modellen sehr großen KIs, die im Moment am Markt sind. Die Idee der ganzen Sache ist, möglichst viele Daten auf einmal in das System einspielen zu können, um dadurch einen besseren Kontext für die KI zu generieren. Dadurch, dass das somit die Fragen dann besser beantwortet werden können. Die größten Modelle, die aktuell am Markt sind, sind meines Wissens nach das von Google, wo fast 1 Million solcher Tokens im Prinzip auch gleichzeitig verarbeitet werden können. Sie können da ein ganzes Buch reinschmeißen und dann im Prinzip Fragen an dieses Buch stellen.
Florian Polak: 00:13:02,720 –> 00:13:36,980
Problem bei der ganzen Sache ist, dass erstens mal ist es ein recht ineffiziente System, weil jedes Mal, wenn Sie eine Frage stellen an diese Daten, muss das gesamte Buch neu analysiert werden, was eine sehr ineffiziente Art und Weise ist. Und zwar sind diese Modelle zwar mittlerweile immer billiger, aber sie haben immer noch das Problem, dass wenn sie sehr, sehr viele Fragen stellen wollen, was bei Studien häufig vorkommt, dass ihnen dann ziemlich viel Kosten entstehen können. Und das zweite ist, was wahrscheinlich noch viel wichtiger ist Nur weil Sie einen größeren Kontext haben, heißt das nicht, dass die Antwort besser wird.
Florian Polak: 00:13:37,640 –> 00:14:14,030
Unbedingt. Zwar wird das System einen größeren Kontext haben und wird besser verstehen, um was es hier eigentlich geht. Also was hier die Studie zum Beispiel ist, heißt aber nicht, dass es eine präzise Antwort geben wird. Da komme ich ja schon zum nächsten Punkt. Warum sind denn solche KI Antworten manchmal so oberflächlich? Hintergrund der ganzen Sache ist, dass diese KIs im Prinzip darauf trainiert sind, möglichst natürlich richtige Aussagen zu treffen und keine falschen Antworten zu liefern. Eine Methode, um so was zu machen, ist im Prinzip den Kontext, die Kontextfenster zu erhöhen und mehr Daten reinzuspielen, um mehr Informationen zu zu liefern.
Florian Polak: 00:14:14,540 –> 00:14:58,820
Das Problem mit der ganzen Sache ist, dass das System darauf trainiert ist, bloß keine Fehler zu machen und bloß keine falschen Antworten zu liefern. Und aus diesem Grund im Prinzip versucht, eine Antwort zu generieren, die möglichst allgemeingültig ist und ja nicht falsch ist und in dem Kontext eben richtig ist oder und und und lieber eine oberflächliche Antwort gibt, als dass es einen tatsächlichen Fehler macht. Und das ist im Prinzip auch der Grund, warum dann im Prinzip seine Antwort relativ oberflächlich und ja allgemeingültig, aber vielleicht nicht besonders hilfreich für eine Studie ist. Was zur Folge hat das, dass diese Systeme tatsächlich in manchen Studien einfach gar nicht richtig oder gut eingesetzt werden können.
Florian Polak: 00:14:59,900 –> 00:15:41,120
Das ist so das Hauptthema. Das heißt, man muss sich ein bisschen bei diesen gängigen KI Systemen überlegen. Geht man das Risiko ein, dass das Ding halluziniert oder möchte man lieber oberflächliche Antworten haben? Und das ist im Prinzip das Hauptthema, was gerade am Markt mit diesen KI Modellen das problematisch ist. Wir gehen ein bisschen in eine andere Richtung und wir haben. Grundsätzlich werde ich ein bisschen erzählen, wie wir die Infrastruktur hinten aufgebaut haben, um genau diese beiden Probleme nicht zu haben, sondern um wirklich sehr, sehr tief reinzugehen, sehr, sehr präzise Antworten zu generieren, auch bei sehr großen Datenmengen, ohne das Problem zu haben, dass wir auf der anderen Seite Halluzinierung Stimmen haben oder die Antworten einfach sehr generisch sind.
Florian Polak: 00:15:42,980 –> 00:16:30,260
Im Prinzip Was macht unsere KI eigentlich oder was macht das System dahinter? Wir haben einen Text hier im Beispiel ist es jetzt ein Transkript. Wir haben zum Beispiel einen Audiofall von Ihnen bekommen. Das wurde von uns transkribiert. Das heißt, wir haben ein Wortprotokoll des Interviews und jetzt geht unser System über diesen Text und bricht diesen Text auf in Themenblöcke. Das heißt, es nennt sich im Fachsprache nennt sich das Ganze Junking, Das heißt im Prinzip wir wir. Ein System geht über diesen Text und schaut sich an, wo beginnt ein Thema und wo hört es wieder auf und generiert dann ebensolche solche Inhaltsblöcke und bricht diesen langen Text, der ja auch bei einer Stunde Interview mehrere 20 30 Seiten lang sein kann, in kleine Blöcke auf, die dann wiederum abgelegt werden in einem eigenen Datenbanksystem.
Florian Polak: 00:16:30,260 –> 00:17:12,619
Das Datenbanksystem nennt sich Vektor Datenbank. Es ist im Prinzip ein Datenbanksystem, das gut geeignet ist, Inhalte miteinander zu vergleichen. Das heißt, man kann sich vorstellen, ein ganzes Interview wird aufgebrochen. Man hat dann beispielsweise 1000 solche Themenblöcke und diese Themenblöcke werden dann auf dieser Datenbank als Graphen, also in einen mathematischen Wert umgewandelt und auf diese Datenbank abgelegt. Wenn Sie jetzt eine Frage haben und beispielsweise wissen wollen okay, fanden die Teilnehmer. Immer den Kunden Service gut und das System wird diese Frage wiederum analysieren. Um was geht es hier in Aufbrechen in so einen Themenblock und diesen Themenblock ebenfalls auf diese Vektordatenbank ablegen.
Florian Polak: 00:17:13,700 –> 00:17:56,060
Jetzt hat man diese zwei Themenblöcke und das System ist ganz gut geeignet zu vergleichen, Wie nah sind die aneinander dran? Das heißt, das System sucht dann auf Ihre Antwort alle relevanten Stellen in diesem Transkript raus, die geeignet sind, um Ihre Frage zu beantworten. Und diese Textblöcke werden dann genommen, werden dann eben so eine KI weitergegeben, die nicht mehr das ganze Transkript liest, sondern ausschließlich diese Themenblöcke. Daraus dann im Prinzip eine Antwort generiert und ihre Frage beantwortet hat zwei Vorteile Nummer eins Wir, die grundsätzlich. Die Antwort ist sehr, sehr präzise, weil sie im Prinzip wirklich ausschließlich den Text liest, der relevant ist, um Ihre Frage zu beantworten.
Florian Polak: 00:17:56,720 –> 00:18:30,620
Und das Zweite ist Wir können eine Rückverfolgbarkeit von Informationen garantieren. Das heißt, wir zeigen Ihnen grundsätzlich nicht nur einfach nur die Antwort der KI an, sondern wir zeigen Ihnen auch alle Textblöcke an, die relevant waren, um diese Frage zu beantworten. Und auf einmal können wir eine Rückverfolgbarkeit garantieren, was zur Folge hat, dass wir nicht nur Ihre Frage beantworten können, sondern sie das Ganze auch einfach überprüfen können. Das ist im Prinzip unser System und wir haben jetzt verschiedene Anwendungsfelder, wo wir das im Prinzip einsetzen. Erstes Thema ist beispielsweise bei diesem Kodieren von offenen Antworten in quantitativen Studien.
Florian Polak: 00:18:30,740 –> 00:19:15,890
Also beispielsweise Sie haben 1000 Antworten von Teilnehmern einer Onlinestudie, die im Prinzip einfach Informationen geben, was Sie zu dem Kundenservice gesagt haben. Jeder dieser Aussagen wird im Prinzip jetzt wiederum selbes Prinzip aufgebrochen in diese Themenblöcke. Manchmal ist so eine Antwort ja durchaus sehr, sehr lange. Dann sind es dann mehrere Themenblöcke, die werden wiederum abgelegt und die Codes, die im Prinzip genutzt werden, um das Ganze zu verdichten, werden ebenfalls als Themenblöcke abgelegt. Und dann wird eigentlich nur noch miteinander verglichen Was passt gut, welche Codes passen gut zu dieser Aussage? Und so kann man diese Ergebnisse relativ schnell verdichten, ohne die Gefahr zu gehen, dass die Ergebnisse falsch zugeordnet werden.
Florian Polak: 00:19:17,390 –> 00:19:58,070
Natürlich kann man da relativ lange Studien einfügen. Also die größten, die wir jetzt mittlerweile haben, waren glaube ich 20.000 Textnennungen, die dann im Prinzip dort nur System durch gejagt wurden. Verschiedene Datenformate unterstützen wir. Klassisch sind natürlich Excel oder SS, da dann das ganze Thema wird einfach einmal durch codiert. Das dauert im Durchschnitt für so 1000 Nennungen zirka zwei Minuten. Man kann sich die Ergebnisse natürlich wieder anschauen, kann eventuell auch nachbessern, wenn man das möchte, also einen anderen Code zum Beispiel verwenden. Oder man kann sogar dem System sagen, hier sind alle Nennungen, finden wir einen guten Code bei, nachdem ich das Ganze verdichten kann drüben.
Florian Polak: 00:19:58,520 –> 00:20:45,780
Und das Ganze im Prinzip dann durch Codieren lassen. Und die Formate können dann wieder als Excel oder SSDatei wieder exportiert werden. Das nächste Thema ist eher in der qualitativen Forschung. Hmmm. In der qualitativen Forschung geht es mir darum, Interviews oder Gruppendiskussionen tatsächlich zuerst einmal in Text zu transkribieren. Da haben wir Verschiedenes, verschiedenste Spracherkennungsalgorithmen für die verschiedenen Sprachen. Im Regelfall können wir alle romanischen Sprachen gut abdecken. Wir können vor allem im Deutschen, wo unser Fokus liegt, auch die verschiedenen Dialekte und Akzente auch ganz gut im Prinzip kennen. Je nach Aufnahmebedingungen schaffen wir da im Durchschnitt circa 95 % Genauigkeit.
Florian Polak: 00:20:45,780 –> 00:21:34,050
Das entspricht einer geschulten Transkriptionspersonen, die im Prinzip daneben sitzt und jedes Wort mitprotokolliert. Dann haben Sie mal den. Das Wortprotokoll, also im Prinzip das Transkript des Interviews oder der Gruppendiskussion. Und wenn es sich um eine Gruppendiskussion handelt, kann zum Beispiel dann automatisch auch das Gespräch nach Sprechern aufgebrochen werden. Das heißt, wenn Sie beispielsweise fünf Leute zu einem Thema befragen, wird dann schon aufgebrochen nach Sprecher, ein Sprecher, zwei Sprecher, drei Sprecher vier und fünf natürlich. Und sie können nachher dann wiederum, weil das System das Ganze dann aufbricht, wiederum sich aussuchen. Okay, möchte ich eine Analyse über alle Teilnehmer machen oder möchte ich wirklich tatsächlich einfach für jeden Sprecher relevante Informationen rausziehen?
Florian Polak: 00:21:35,250 –> 00:22:16,650
Und das System gibt Ihnen dann im Prinzip die Antworten auf Ihre Fragen. Das kann zum Beispiel der Leitfaden sein, den Sie hinterlegen oder auch Ihre Research fragen, um spezifisch nach bestimmten Informationen zu suchen. Das Spannende der Sache ist Sie können ein Interview hochladen und das analysieren. Oder Sie können ein ganzes Studio hochladen, um viele verschiedene Informationen aus den beispielsweise zehn Interviews rauszuziehen, um dann gemeinschaftlich einfach sich ein Bild zu machen über diese verschiedenen qualitativen Studien, die Sie da durchgeführt haben. Und der letzte Punkt ist wirklich tatsächlich, dass wir unser neuestes Modul eigentlich, dass wir tatsächlich große Mengen an Daten im Prinzip anbinden können.
Florian Polak: 00:22:16,650 –> 00:23:03,240
Ein klassisches Beispiel wären zum Beispiel Social Media Kanäle, die Sie per API Schnittstelle zum Beispiel anschließen können, um dagegen dann Fragen zu stellen. Sprich da werden Datenpunkte im Prinzip von Ihnen in unser System eingespielt, maschinenlesbar. Der Text muss das Ganze sein und dann können Sie tatsächlich Ihre Fragen gegen diese Datensätze stellen. Das können Exceldateien sein, das können Textdateien sein, über eine API zum Beispiel. Das können aber auch Transkripte von Interviews natürlich sein, um dann wirklich eine gesamt einheitliche Auswertung über diesen diese ganze Studie zu machen. Wunderbar geeignet natürlich für andere Communities, wo es grundsätzlich relativ viele Daten gibt, wo auch über mehrere Tage oder Wochen hinaus gewisse Informationen gesammelt werden von Usern, um dann wirklich so eine Auswertung tatsächlich zu machen.
Florian Polak: 00:23:03,870 –> 00:23:55,080
Das System zeigt ihnen dann immer die Antwort an, aber auch die Referenzen wirklich von den jeweiligen Textblöcken wiederum woher die Informationen eigentlich kommen, sodass sie dann leicht eine Möglichkeit haben, das Ganze zu überprüfen. Genau. Als Epischnittstelle können Sie das natürlich anschließen. Ähm, grundsätzlich wie funktioniert unser System? Gibt grundsätzlich mal zwei Möglichkeiten, wieder zusammenzuarbeiten. Wir können das Ganze bei Ihnen auf dem Server installieren. Das wäre dann so eine On Premise Installation. Das heißt, dann wird das Ganze wirklich auf Ihren Server betrieben. Keine Daten verlassen Ihr Unternehmensnetzwerk. Der einzige Nachteil, den Sie da haben, abgesehen davon, dass es ein bisschen umständlich ist, ist, dass Sie da relativ starke Server brauchen, inklusive solche Grafikkarten, also GPUs genannt, die geeignet sind, im Prinzip, um diese Systeme sehr performant laufen zu lassen.
Florian Polak: 00:23:55,470 –> 00:24:39,750
Oder sie entschließen sich, das Ganze auch mit uns zusammenzuarbeiten in der Cloud. Da garantieren wir Ihnen wie gesagt, dass die Daten ausschließlich in Deutschland verarbeitet werden. Das ist dann im Prinzip auf unserem Server, der in Nürnberg steht. Serveranbieter ist ein deutsches Unternehmen namens Hetzner und wo im Prinzip dann die Daten analysieren zu lassen. Ähm, grundsätzlich natürlich sind diese Systeme hinreichend gesichert, sprich wir verarbeiten ihre Daten auch wirklich nur so, wie sie das Ganze von uns wünschen. Gibt da verschiedene Möglichkeiten, wie wir zusammenarbeiten können. Man kann auch eigene Datentrainings für sie machen, wenn sie das wünschen. Und es gibt natürlich auch die Möglichkeit in anderen EU Ländern beispielsweise einen Cloudserver aufzubauen, was wir grundsätzlich auch schon in der Vergangenheit gemacht haben.
Florian Polak: 00:24:41,390 –> 00:25:18,530
Zu den Preisen gibt es zwei verschiedene Art und Weise, mit uns zusammenzuarbeiten. Das eine Thema wäre wirklich so einer on demand. Das heißt wirklich, Sie haben ein Projekt, Sie kommen auf uns zu und sagen, wir wollen jetzt dieses Projekt mit ihnen durchführen. Wir machen ein Angebot und rechnen dann nach der Studie im Prinzip ab. Da rechnen wir grundsätzlich immer nach Datensätzen ab, also im Prinzip, wenn es sich um qualitative Interviews handelt. Das rechnen wir meistens über Audiostunden ab. Wenn es sich um Excel Dateien handelt, die abgerechnet werden müssen, haben Sie, zahlen Sie einen Cent pro Betrag für eine Pro Excel Zelle, also pro Nennung des Befragten und rechnen das Ganze völlig flexibel ab.
Florian Polak: 00:25:18,530 –> 00:25:54,140
Keine Bindung, oder? Wir haben auch natürlich das Corporate Offer. Das machen wir bei größeren Kunden mit uns, dass sie einen jährlichen Fixpreis haben, dann haben sie keine Mengeneinschränkung, können das Ganze mit uns machen nach Lust und Laune und können auch bauen das Ganze für sie im Prinzip dadrauf. Das kann natürlich auch alles kombiniert werden. Das heißt, es gibt natürlich auch die Möglichkeit, dass man zum Beispiel eine qualitative Studie durchführt, die Ergebnisse dann verdichtet. Im Prinzip. Beispielsweise im Quantenmodul, dass man dann wirklich das Ganze auf wirkliche Wortnennungen verdichtet und das Ganze kodiert, um dann eine sehr, sehr gute Auswertung zu kriegen.
Florian Polak: 00:25:54,140 –> 00:26:31,070
Und um sich einen Report im Prinzip schnell herzurichten. Das wäre auch schon alles von meinem Webinar. Jetzt würde ich ganz kurz auf die Fragen eingehen, die Sie grundsätzlich hier im Chat gestellt haben. So gibt es die Möglichkeit, Audiodateien zu testen zu lassen. Starke Dialekt aus Österreich zum Beispiel. Ja, grundsätzlich. Sie können das bei uns auch immer alles testen. Das heißt da einfach uns gerne unverbindlich einfach schreiben. Wir bieten natürlich immer die Möglichkeit an, das Ganze auszuprobieren, sei das jetzt eben bei Audiodateien mit Akzenten zum Beispiel, aber auch natürlich bei Excel Studien, dass Sie das mal ausprobieren können und sich von der Qualität überzeugen.
Florian Polak: 00:26:31,880 –> 00:27:11,870
Bei den Akzenten Grundsätzlich gilt je in Österreich vor allem je weiter östlich, desto leichter, je weiter westlich, desto schwieriger. Schweizer Akzente und Dialekte sind tatsächlich ein bisschen problematisch, weil es keine keine einheitliche Art gibt, wie man Schweizerdeutsch schreibt. Deswegen gibt es auch wenig Möglichkeiten, da leicht einen Spracherkennungsalgorithmus aufzubauen. Wir haben aber schon die verschiedensten Projekte auch in Österreich gemacht. Sprich einfach kontaktieren und einfach ausprobieren, würde ich vorschlagen. Dann die nächste Frage war dann auch noch Können auch Transkripte von Face to Face Gruppendiskussionen mit Zuordnung der sprechenden Person gemacht werden oder nur von anderen Gruppen? Face to face geht auch.
Florian Polak: 00:27:11,870 –> 00:27:53,330
Wir brauchen grundsätzlich eine Aufnahme in einer Art oder oder der anderen. Also beispielsweise, wenn Sie wirklich eine Face to Face Studie haben und das Ganze aufnehmen, können Sie nachher die Audiodateien nehmen, hochspielen und das Ganze dann im Prinzip transkribieren lassen. Wir wir machen das nicht über die verschiedenen Kanäle, also beispielsweise bei einem Online Meetings über Teams gibt es ja die verschiedenen Sprecherkanäle und im Regelfall hat man bei der Transkription dann so eine Aufteilung nach den verschiedenen Kanälen. Wir machen das Ganze über eine eigene Sprechererkennung, das heißt, wir haben da einen eigenen Algorithmus drinnen, der die Unterschiede in den Stimmlagen erkennt und das Gespräch danach im Prinzip auf aufbricht, quasi.
Florian Polak: 00:27:54,260 –> 00:28:28,400
Bedeutet aber natürlich auch, dass das wir nicht wissen, dass ich zum Beispiel der Florian Pollack bin, sondern wir wissen eigentlich dann auch nur okay. Es gab fünf Sprecher in diesem Gespräch und folgender Sprechereinsatz folgende Sachen gesagt natürlich, wenn man nachher die Informationen wieder braucht, um eine Analyse zu fahren, beispielsweise, dass man die Analyse machen möchte, über was die weiblichen Teilnehmer der Studie gesagt haben, dann kann man diese Referenzen wieder einfügen. Das müsste dann manuell im Nachhinein gemacht werden von Ihnen, geht aber recht schnell, um dann nachher im Prinzip in der Auswertung auf der Ebene auch noch machen zu können.
Florian Polak: 00:28:29,840 –> 00:29:11,360
Haben Sie auch Familien mit Schweizer deutschen Dialekten? Ja, haben wir. Schweizerdeutsche Dialekte sind leider etwas schwierig, muss ich noch dazu sagen. Wir haben mittlerweile ein neues Modell, das glaub ich nächste Woche rauskommt, das tatsächlich für Schweizerdeutsch Ergebnisse bringt, die, sagen wir mal deutlich besser sind als das, was sie bisher am Markt kennen. Wir müssten dann allerdings auch ausprobieren, wie die wie die Qualität wirklich ist, weil das eben ein sehr, sehr neues Modell ist. Grundsätzlich ist das ein bisschen schwieriger natürlich als österreichisch oder oder deutsch Deutsch mit den verschiedenen Dialekten und Akzenten dort. Und dann kann man von Ihnen anonymisierte, pseudonymisierte Beispiele für eine Textauswertung erhalten, um ein Gefühl für die Ergebnistypen zu bekommen.
Florian Polak: 00:29:11,360 –> 00:29:52,440
Ja, können Sie, wenn Sie grundsätzlich mit uns machen. Meistens dann so eine Demo. Da haben wir auch eine Demostudie drinnen, wo Sie das Ganze sich einmal anschauen können und durchaus dann im Prinzip das Ganze auch verwenden können, um selber sich zu überprüfen, ob das System passt oder nicht. Dann kann die ja vorher die Webseite oder Dokumente crawlen und Spezialbegriffe Spezialabkürzungen zu identifizieren. Wir haben viele Fachbegriffe, die auch von Kunden verwendet werden. Grundsätzlich. Das Thema Spezialbegriffe ist immer wieder relevant. Für qualitative Studien ist es insbesondere dann relevant, weil die Spracherkennung basiert nämlich auch auf dem üblichen Sprachgebrauch.
Florian Polak: 00:29:52,860 –> 00:30:42,570
Wenn es dann Spezialbegriffe gibt, Eigennamen, Firmennamen beispielsweise. Sowas kann im Regelfall sehr, sehr einfach im Prinzip hochgeladen werden, in dem sie eigentlich ein Level hochladen, Ob wir es von der Webseite crawlen. Grundsätzlich einen Service. Wir haben theoretisch Crawler mit so was zu machen. Effizienter wäre es wahrscheinlich, wenn wir einfach im Prinzip sie uns die Webseite sagen. Wir schauen uns das Ganze für Sie an, erstellen wir eine Excelliste an diesen Fachbegriffen und laden die einmal hoch. Das dauert im Regelfall zwei drei Minuten, ist recht schnell gemacht und dann werden die Begriffe auch richtig erkannt. Üblicherweise, wenn es sich um Webbegriffe handelt, die auf Webseiten sind, macht es in der Textauswertung gar nicht mal so groß eine Rolle, weil die KI Systeme im Regelfall mit sehr, sehr großen Datenmengen gefüttert wurden, sodass auch Spezialbegriffe dann auch richtig erkannt werden.
Florian Polak: 00:30:42,570 –> 00:31:26,060
Also ein Kontext passt dann im Regelfall ganz gut. Insofern sollte das damit auch eher kein Problem sein. Und welche Sprachen können Sie abbilden? Alle europäischen und auch nichteuropäischen Sprachen. Grundsätzlich also was auf jeden Fall sehr, sehr gut funktioniert, sind die romanischen Sprachen, also Deutsch, Englisch, Französisch, Spanisch, Italienisch. Wir hatten dann aber auch Niederländisch, Dänisch, die auch gut funktioniert haben. Im Englischen natürlich die verschiedenen Sprachgruppen, die wir haben. Also wir hatten tatsächlich auch eine Studie, die mit singapurianischen Akzenten waren, wo ich in der Spracherkennung, also ich persönlich hätte weniger verstanden als unsere KI da tatsächlich. Also da gibt es auch die verschiedensten Möglichkeiten.
Florian Polak: 00:31:26,070 –> 00:31:56,130
Wir haben aber auch die Möglichkeit, wenn es, sagen wir mal, eine sehr exotische Sprache ist, die nicht sehr häufig vorkommt, hier noch mit anderen Anbietern zusammenzuarbeiten. Dann müssten wir uns aber im konkreten Fall anschauen, was sie da brauchen. Und auch da müssen wir uns genau noch mal erkundigen, wie das Ganze funktioniert, dass wir auch garantieren können, dass die Daten ausschließlich auf unserem Server verarbeitet werden, weil das dann halt eine Spracherkennung ist, die wir nicht anbieten, da gerne einfach auf uns zutreten. Wir können dann im Spezialfall gerne noch mal drüber reden, wenn wir schon beim Thema Sprache sind.
Florian Polak: 00:31:56,160 –> 00:32:42,570
Ein wichtiger Punkt geht auch Beispiel insbesondere bei qualitativen Studien. Sie können auch im Prinzip, wenn Sie einen Leitfaden beispielsweise auf Deutsch haben und die Studien mehrsprachig sind, also beispielsweise auf Englisch und auf Deutsch, dann können Sie das Ganze transkribieren lassen, auf Englisch und jeweils auf Deutsch und dann aber den Leitfaden nehmen, um den auch auf die englischen Transkripte gegen die zu stellen, sodass die Antworten aus dem Kontext, aus dem englischen Transkript raus extrahiert werden, um dann im Prinzip aber auf Deutsch übersetzt werden. Das funktioniert. Es ist genaugenommen kein Übersetzungsprogramm, sondern es ist, dass die KI versteht den Kontext der anderen Sprache, weil die Trainingsdaten in sowohl auf Englisch als auch auf Deutsch zur Verfügung waren.
Florian Polak: 00:32:42,840 –> 00:33:17,060
Das funktioniert erstaunlich gut. Das heißt, Sie können auch mehrsprachige Studien mit uns durchführen, ohne weitere Probleme. So, dann die nächste Frage Können mehrere Sprachen gleichzeitig verboten werden? Ja, das war kurz die Frage, die ich gerade beantwortet haben. Also zum Beispiel für Studien in Belgien. Ja, das geht grundsätzlich. Also wenn Sie eine französischsprachige Studie haben und das andere wäre Flämisch, zum Beispiel, sollte das kein Problem sein, müssten wir das einmal transkribieren in die jeweilige Sprache. Und wenn Sie dann Ihren Leitfaden aus auf beispielsweise Deutsch haben, werden die Antworten im Prinzip genutzt, um dann ein Ergebnis zu produzieren.
Florian Polak: 00:33:17,070 –> 00:34:08,850
Also Ihre Antwort zu der Frage zu beantworten. Wenn Sie denn die Zitate haben wollen, sind die dann logischerweise aber in der Originalsprache. Und die letzte Frage Können bei quantitativen Studien demografische Daten mit offenen Ländern verknüpft werden dann die Texte danach analysiert, also zum Beispiel bei Männern ist es so und bei Frauen ist es so, Ja, das geht also grundsätzlich. Das wäre dann am ehesten unser letztes Modul, von dem ich gesprochen habe, dieses hier, dass Sie dann eine ganze Excel hochladen, wo dann die ganzen relevanten Datenpunkte drinnen sind und sie dann dagegen einfach die Fragen stellen. Also da können Sie dann auch eine Auswertung machen nach Geschlechtern, nach Informationen, die grundsätzlich in diesen Exceldateien drin sind, um relevante Ergebnisse zu machen, kann natürlich auch kombiniert werden mit den anderen Modulen, die wir haben, um dann so ein Excel zu produzieren, gegen das Sie dann im Prinzip Ihre Research Fragen stellen können.
Florian Polak: 00:34:10,320 –> 00:34:46,139
Okay, wunderbar. Dann waren das, glaube ich, alle Fragen. Hatte es noch eine Frage? Können Sie die Preise der Pakete bitte noch mal wiederholen? Wir haben. Jetzt kommt ein bisschen darauf an, in welcher Kombination Sie das Ganze machen wollen. Bei den Preisen gilt es grundsätzlich zwei Varianten zusammenzuarbeiten Entweder Abrechnung nach Projekten. Das heißt, Sie haben beispielsweise zehn Interviews, die Sie mit uns transkribieren und dann auswerten wollen und wir machen. Ich gebe Ihnen einen Preis, nachdem Sie das Ganze auswerten können und sie zahlen dann nach Durchführung des Projektes. Oder die Variante ist, dass Sie einen Pauschalpreis mit uns machen.
Florian Polak: 00:34:46,139 –> 00:35:17,370
Da kommt es wie gesagt darauf an, welche Funktionen Sie gerne haben wollen. Und dann machen wir einen Pauschalpreis pro Jahr. Und dann ist es uns auch egal, wie viele Studien Sie darüber laufen lassen. Kommt darauf an, in welchem Kontext Sie machen. Das Corporate aber macht im Regelfall dann Sinn, wenn Sie viele Datenmengen haben oder sehr, sehr viele Studien durchführen. Ansonsten würde ich Ihnen wahrscheinlich dazu raten, das Ganze auf Projektbasis Minus zu machen. Gut, dann vielen Dank, dass Sie heute ins Webinar gekommen sind. Wenn Sie grundsätzlich noch Fragen haben Sie können. Meine Emailadresse finden Sie hier unten.
Florian Polak: 00:35:17,820 –> 00:35:38,190
Sie können uns jederzeit natürlich auch schreiben. Grundsätzlich werden wir auch, glaube ich, eine Zusammenfassung von diesem Webinar auch nochmal zirkulieren. Die Zusammenfassung ist dann auch schnell generiert für unsere Studie. Dann haben Sie da auch schon mal einen Überblick, wie gut das System eigentlich erarbeitet und habe mich sehr gefreut, dass Sie heute gekommen sind. Und ich wünsche Ihnen noch einen schönen Nachmittag. Vielen Dank!
Ein umfassender Überblick über die Webinarthemen
Das Webinar bot den Teilnehmern eine systematische Darstellung der Rolle der KI in der Marktforschung und behandelte folgende Themen:
- Die Grundlagen von KI-Systemen und ihre Anwendung in der Marktforschung.
- Strategien zur Bewältigung gängiger KI-Integrationsherausforderungen, mit einem Fokus auf die speziellen Methoden von Tucan.ai.
- Ein detaillierter Einblick in die Produktpalette von Tucan.ai mit Fallstudien, die die Problemlösungsfähigkeiten in realen Szenarien demonstrieren.
- Die Bedeutung der Datensicherheit bei KI-Anwendungen und das Engagement für den Schutz der Kundendaten.
Zentrale Einsichten und Diskussionspunkte
Ein Höhepunkt des Webinars war Florian Polaks Erklärung von "KI-Halluzinationen". Er nutzte die Analogie zu einem Bibliothekar, um das Data Chunking und die Vektordatenbanken von Tucan.ai zu beschreiben, die dafür sorgen, dass die KI wie ein erfahrener Bibliothekar effizient durch riesige Mengen an Informationen sortieren kann, um genau die Erkenntnisse zu finden, die benötigt werden, ohne sich ablenken zu lassen.
Praktische Tipps für Marktforschungsexperten
Das Webinar enthielt umsetzbare Ratschläge, unter anderem:
- Implementierung der Anti-Halluzination-Mechanismen zur Validierung von KI-generierten Erkenntnissen, wobei Polak betont: "Genauigkeit ist der Eckpfeiler unserer KI-Lösungen."
- Anwendung von KI zur schnellen Codierung offener Umfrageantworten, wodurch stundenlange manuelle Arbeit in eine Aufgabe verwandelt wird, die nur wenige Minuten dauert.
- Nutzung der mehrsprachigen Fähigkeiten von Tucan.ai zur Analyse verschiedener Datensätze, um umfassende und integrative Forschungsstudien zu ermöglichen.
Der KI-Vorteil
Indem sie die spezifischen Herausforderungen von Marktforschern mit modernsten KI-Lösungen angehen, können Marktforscher nicht nur ihren Forschungsprozess rationalisieren, sondern auch zuverlässigere und umsetzbare Erkenntnisse gewinnen. Ob für Nischenstudien oder groß angelegte Projekte, KI-Tools können auf die besonderen Anforderungen jeder Forschungsinitiative zugeschnitten werden.
Steigern Sie Ihre Produktivität um das Zehnfache!

Keine Lust mehr auf neue KI Tools mit mangelnder Qualität?
Wahrscheinlich liest du das hier, weil du mit den Lösungen und Technologien, die der KI-Hype für Marktforscher hervorgebracht hat, nicht zufrieden bist.
Und das solltest du auch nicht sein.
Künstliche Intelligenz wurde zunächst als eine Technologie erdacht, die die Arbeitsbelastung von Menschen massiv reduzieren, die Automatisierung vorantreiben und neue Arbeitsweisen ermöglichen würde. ChatGPT hat bewiesen, dass KI in der Lage ist, Menschen bei der Arbeit zu unterstützen, aber anspruchsvolle Branchen wie die Marktforschung erfordern mehr als nur ein schönes Frontend, das mit einem generalistischen und grundlegenden Dienst wie GPT 3.5 verbunden ist. Heute besteht mehr denn je ein Bedarf an hochwertigen KI-Lösungen für Marktforscher.

Aber wie sieht eine hochwertige KI-Lösung aus?
Die wertvollste Ressource eines Marktforschungsunternehmens sind die Forscher, die in der Lage sind, intelligente Studien zu konzipieren und auszuwerten. Die Qualität einer Lösung wird also dadurch bestimmt, wie leistungsfähig die Unterstützungsmechanismen dieser Lösung sind. KI-Plattformen müssen unaufdringlich und einfach zu bedienen sein und sollten niemals die Fähigkeit des Menschen beeinträchtigen, in intellektuellen Angelegenheiten das letzte Wort zu haben. Zugleich sollten sie den Zeitaufwand für rudimentäre Aufgaben massiv reduzieren und neue Arbeitsweisen ermöglichen.

tucan.ai - eine bewährte Plattform für Marktforschung.
Wie unsere Auszeichnung als innovativste Marktforschungslösung des Jahres 2023 zeigt, ist tucan.ai eine echte geschäftsfähige KI-Lösung, die lange vor dem KI-Hype entstanden ist und eigene Algorithmen und Modelle nutzt. Das befähigt uns unsere Dienste sowohl online als auch offline anzubieten und sie perfekt an die Workflows, Prozesse und IT-Infrastruktur unserer Partner anzupassen. Es ist also kein Wunder, dass einige der größten Marktforschungsunternehmen unsere Lösung schon heute implementieren, um sicherzustellen, dass sie der Zeit immer einen Schritt voraus sind.

Wir befähigen qualitative Forscher...
Unser hochmoderner KI-Assistent ermöglicht es, Interviews und Fokusgruppen automatisch nach vordefinierten Kategorien oder Themen zu kodieren. Neben der Kodierung der Antworten können Forscher zusätzliche Analyseaufgaben oder Datenpunkte definieren, die sie dem Erhebungsmedium entnehmen möchten und erhalten die Ergebnisse in nur wenigen Minuten. Das ist beachtlich, wenn man bedenkt, dass diese Prozesse, wenn sie manuell ausgeführt werden, oft mehrere Tage in Anspruch nehmen. Über die Marktforschung hinaus kann diese Funktion auch für Meinungsumfragen und ähnliche Bereiche genutzt werden, die auf die Analyse qualitativer Daten angewiesen sind. Erfahre mehr in unserem Factsheet "AI-powered encoding with Tucan.ai" oder kontaktiere uns direkt für eine Kopie der Dokumentation unseres viralen Webinars zu qualitativer Forschung und künstlicher Intelligenz.

...und quantitative Forscher!
Unsere bestehenden Kunden aus der Marktforschung bitten uns seit längerem um die Entwicklung von Funktionalitäten, die bei der quantitativen Marktforschung helfen. Unser erstes Update für quantitative Forschung macht es möglich, eine unbegrenzte Anzahl von Datenpunkten auf der Grundlage eines vordefinierten Code-Plans zu analysieren oder sogar die KI zu bitten, einen neuen Code-Plan zu erstellen. In unserem Test analysierte ein Forscher 400 Datenpunkte mit einem unvollständigen Codeplan. Der KI-Assistent hatte die Aufgabe, den Codeplan auf der Grundlage der gegebenen Daten zu vervollständigen und dann alle Einträge auf der Grundlage aller Codeplan-Kategorien zu quantifizieren. Trotz perfekter Ergebnisse dauerte dieser Prozess nur eine Minute und 43 Sekunden, vom Öffnen unserer Plattform bis zum Öffnen der exportierten Ergebnisse. Das ist 228 Mal schneller, als selbst ein schneller Forscher es manuell hätte tun können. Wenn du mehr über unsere neuen quantitativen Forschungsfunktionen erfahren möchtest, kontaktiere uns direkt oder melde dich für unser kommendes Webinar zu quantiativer Marktforschung und künstlicher Intelligenz an.
Kontaktiere uns noch heute und finde heraus, wie tucan.ai deine Studien revolutioniert, indem es Prozesse optimiert und Forschern ermöglicht, ihre Ergebnisse in einem einzigen Monat zu verzehnfachen.

Wenn du mehr über Tucan.ai's Lösungen für Teams und Unternehmen erfahren möchtest, vereinbare bitte einen kurzen Online-Termin mit unserem CEO, Florian Polak (florian@tucan.ai).
Kundenbeiträge
Was sie über uns sagen
![]()
"We at Axel Springer have been using Tucan.ai for already over two years now, and we continue to be very satisfied with the performance of the software and the development process as a whole."
Lars
Axel Springer SE
![]()
"I have known the founding team for over a year. At Porsche, we are very satisfied with their work so far. I have recommended the use of Tucan.ai to my colleagues and business partners and I have been getting highly positive feedback back across the board - both on the service and the software."
Oliver
Porsche AG

"Tucan.ai has been a game-changer for our team. The software is incredibly intuitive and easy to use. It has saved us countless hours of work and has allowed us to focus on what really matters - our clients. I would highly recommend Tucan.ai to anyone looking for an AI-powered productivity tool."
Alex
Docu Tools
Tucan.ai revolutioniert qualitative Marktforschung mit KI für Codierung und smarte Gesprächsarchivierung

Sieger des Startup-Pitches von Marktforschung.de, Norstat, GIM, ADM und BB Recruiting
Im vergangenen April fand der sechste Startup Pitch von marktforschung.de und Consulting.de statt, ein deutschlandweiter Online-Wettbewerb für Marktforschung, Consulting und Data Analytics. Vier Startups aus den Feldern KI, UX, CX und Data Analytics durften ihre Geschäftsideen vor einem Fachpublikum und einer hochkarätigen Jury präsentieren. Das Rennen machten dieses Jahr glücklicherweise wir. Mit dem folgenden Video hatte unser Mitgründer Florian Polak Tucan.ai im Vorfeld vorgestellt.
https://www.tucan.ai/wp-content/uploads/2023/06/Marktforschung.de_Video.mp4
Der Wettbewerb wurde vom Branchenverband ADM, der Personalberatung BB Recruiting, den Instituten GIM und mindline sowie dem Online-Feldspezialisten Norstat unterstützt. Sabine Menzel (L’Oréal), Janina Mütze (Civey), Jörg Kunath (mindline), Stephan Telschow (GIM), Arndt Schwaiger (Serial Entrepreneur), Christian Arndt (Hightech Gründerfonds), Birgit Bruns (BB), Roland Abold (ADM) und Sebastian Sorger (Norstat) saßen in der Jury. Marktforschung.de-Geschäftsführer Holger Geißler führte nachher mit Sorger noch ein kurzes Interview. Hier könnt ihr nachlesen, was der Juror und Geschäftsführer von Norstat hier in Deutschland zu sagen hatte:
Interview mit Sebastian Sorger: "Wer Ideen einfach erklären kann, hat einen Vorteil."
Die teilnehmenden Start-ups waren ja in sehr unterschiedlichen Stages. Kann man ein Start-up wie Gutfeel, die kurz vor der Beta-Phase stehen, überhaupt fair mit einem Start-up wie Objective Platform vergleichen, das bereits in drei Ländern mit 60 Mitarbeitenden vertreten ist?
Sebastian Sorger: Ja. Grundlegendes sollte in beiden Phasen verständlich sein: Was ist das Geschäftsmodell? Wie wird ein Mehrwert beim Kunden erzeugt und monetarisiert? Wie tickt der Markt, der Wettbewerb, was ist das Alleinstellungsmerkmal?
Mich hat überrascht, dass im Vergleich zu früheren Pitches wenig Financials von den Start-up genannt wurden. Wie bewertest Du das?
Sebastian Sorger: Ging mir auch so! Vielleicht stand der werbende Charakter gegenüber den Zuschauern im Vordergrund?
Spannend ist doch schon: Wie groß ist der an der Lösung realistisch interessierte Markt, wie lange der Vertriebszyklus und wie kann die Bepreisung funktionieren? Ferner wie viele Early Adopter oder – bei entsprechender Unternehmensreife – Kunden aus dem Majority Market anbeißen könnten, um die Umsatzerlöse (und Produktionskosten) einschätzen zu können. Von dieser Marge gehen die Fixkosten weg (Personal, Reisen, Marketing etc) und man kann mit dem EBITDA dann gut in der P&L abschätzen, wie viel Kapital man braucht.
Welche Meilensteine werden für die Investitionsrunden gesetzt? Klar nennt man da nicht alles, aber zum Beispiel durchaus wie hoch das Funding war oder sein sollte, wie viel man nun einsammeln will, wann man den Break-Even erreicht haben will. Gegenüber einer reinen Investorenrunde wären diese Infos sicherlich gekommen, bzw. eingefordert worden.
Auch die Reifegrade der Start-ups in Bezug auf die Pitch-Präsentationen waren sehr unterschiedlich. Wie entscheidend war in Deiner Wahrnehmung, dass Tucan.AI vergleichsweise überzeugend präsentiert hat?
Sebastian Sorger: Florian von Tucan.AI gelang es das Geschäftsmodell sehr einfach rüberzubringen. Was ist das Problem? Wie soll mit der Lösung das Problem abgestellt werden? Das hat jeder verstanden.
Ich hatte den Eindruck, dass die eigentlich großartige Geschäftsidee von Savio nicht jedem klar geworden ist. Wie erklärst Du Dir, dass Savio nicht weiter vorne gelandet ist? War es ein Nachteil, dass Julian auf Englisch präsentiert hat?
Sebastian Sorger: Vielleicht. Nicht jeder spricht und versteht Englisch gleich gut. Ich hatte das Gefühl Julian hat sich auch zu sehr auf den Text der Folien fokussiert. Ich bin sicher, hätte er seiner Leidenschaft freieren Lauf gelassen, hätte das mehr angesteckt. Es war allerdings auch bis zum Ende nicht klar, wer seine Teilnehmer auf diesem „two-sided-marketplace“ eigentlich sind.
Du achtest immer sehr auf das Gründer-Team. Welche Trends siehst Du da über die Jahre? Gibt es verallgemeinerbare Trends?
Sebastian Sorger: Es sind doch oft relativ junge Gründer. Das ist überhaupt nicht schlecht. Oft werden erfahrene Manager zu einem späteren Zeitpunkt dazu geholt, um Strukturen aufzubauen und das Wachstum zu managen.
Ich frage mich aber, wann VCs / Investoren erkennen, dass es viel Sinn ergeben kann, auch Seniors gleich zu Beginn mit ins Boot zu holen. Dann muss sich aber am Vergütungsmodell etwas ändern. „Nur“ mit vielen Anteilen zu locken reicht dann einfach nicht.
Was für Start-ups würden noch gut zur Norstat-Gruppe passen?
Sebastian Sorger: All jene, die uns im Bereich Felddienstleitungen für qualitative und quantitative Forschung sinnvoll ergänzen. Diese haben eine Technologie und wir bringen die Teilnehmer und organisieren das ganze Drumherum. Wichtig ist dabei: Das Start-Up bringt den Kunden mit, wir sind nicht der Sales Channel. Dann sind wir für (fast) jeden Spaß zu haben, solange wir die Standesregeln einhalten. Bezüglich M&A Bestrebungen fokussieren wir uns eher auf etablierte Unternehmen.
Tucan.ai-Webinar "KI-Codierung von qualitativen Studien" am 6. Juli 2012 auf marktforschung.de
Wie wir durch bereits laufende Projekte mit Kunden aus dieser Branche festgestellt haben, ist das Codieren von Interviews und Fokusgruppen für Marktforscher eine extrem kostenintensive Komponente in ihrem Arbeitsalltag. Tucan.ai erledigt für sie die Transkription, Zusammenfassung sowie Codierung von relevanten Inhalten aus Gesprächen. Der manuelle Aufwand wird durch die KI auf ein Minimum reduziert, ohne dabei die Analyse- und Interpretationshoheit von Expert*innen zu untergraben.
In diesem Webinar wird unser Key-Account-Manager Carlo Glaefeke erläutern, wie Sie mithilfe von Tucan.ai den Zeitaufwand für qualitative Studien um bis zu 80 Prozent reduzieren können. Er wird u.a. die folgenden Punkte für Sie im Detail beleuchten: Erstellung des Leitfadens, Transkribieren der Interviews, Codierung der Antworten und Export der relevanten Daten.
Noch gibt es einige freie Plätze! Hier geht's zur Anmeldung:
Gastbeitrag "Innovative KI-Tools für CX-Forschung" von unserem Mitgründer und CEO Lukas Rintelen
Wenn ihr mehr über den speziellen Nutzen von KI in der CX-Forschung erfahren möchtet, empfehlen wir diesen Gastbeitrag unseres Mitgründers Lukas Rintelen für marktforschung.de:
https://www.tucan.ai/de/blog/automatisierung-in-vollem-gange-diese-neuen-ki-tools-revolutionieren-die-cx-forschung/
Tucan.ai kostenlos testen?

Automatisierung in vollem Gange: Diese neuen KI-Tools revolutionieren die CX-Forschung
In unserem sich rasch digital wandelnden Informationszeitalter wird es immer schwieriger, überzeugende und ansprechende Kundenerlebnisse zu bieten. Marktführer in praktisch allen Branchen stellen die Personalisierung in den Mittelpunkt ihrer Geschäftsstrategie.
So bezeichnete Rodney McMullen, CEO von Kroger, kürzlich Nahtlosigkeit und Personalisierung als zwei sehr zentrale Bereiche, in die der Einzelhandelskonzern jetzt vor allem investiert. In ähnlicher Weise haben die Marktführer in der Bekleidungs- (z. B. Nike), Restaurant- (z. B. Starbucks), Bank- (z. B. JPMorgan Chase) und Heimwerkerbranche (z. B. Home Depot) im vergangenen Jahr erklärt, dass sie sich jetzt strategisch auf Folgendes konzentrieren
nahtlose, personalisierte Omnichannel-Erlebnisse
.
Erhebungen zeigen, dass Kunden, die positive Erfahrungen mit Marken gemacht haben, im Durchschnitt mehr ausgeben und langfristig loyaler sind. Laut einer
Studie von Deloitte
sind sie bereit, bis zu 140 Prozent mehr zu bezahlen, wenn sie eine positive Erfahrung mit einer Marke gemacht haben.
Außerdem wissen wir, dass die Verbraucher der Generationen Y und Z in erster Linie Markenerlebnisse gegenüber Produkten bevorzugen. Das bedeutet nicht unbedingt, dass sie nur in den Urlaub fahren wollen, anstatt ihr Geld für trendige Turnschuhe auszugeben: McKinsey dokumentiert ein Wiederaufleben der Nachfrage nach "echten" Einkaufserlebnissen.
Nun stellt sich die Frage: Welchen Beitrag können KI und ML zur Optimierung von Kundenerlebnissen, Nutzerbindung und Konversionen leisten?
Werfen wir zunächst einen Blick auf die aktuelle Situation in der Marktforschung im Allgemeinen, bevor wir näher darauf eingehen, wie und wofür Machine- und Deep-Learning-Technologien in der CX-Forschung eingesetzt werden können und welche Tools und Anbieter sich derzeit besonderer Beliebtheit erfreuen.
Einsatz von KI nimmt branchenübergreifend rasch zu
Wir sind jetzt an einem Punkt angelangt, an dem sich Wettbewerbsvorteile zunehmend aus der Fähigkeit ergeben, große Mengen an Kundendaten sorgfältig zu erfassen, zu analysieren und zu verarbeiten und KI/ML effektiv zu nutzen, um Customer Journeys besser zu verstehen, zu gestalten und zu verwalten.
Um wirkungsvolle Erlebnisse zu schaffen, benötigen Unternehmen fortlaufende Erkenntnisse, die auf einem umfassenden, tiefgreifenden Verständnis ihrer Kunden basieren. In digitalisierten, schnelllebigen Märkten besteht ein Bedarf an innovativer, agiler und halbautomatischer CX-Forschung, die verschiedene Analysemethoden kombiniert und KI/ML gezielt einsetzt. Vor allem diesseits des Atlantiks ist der Weg, der vor uns liegt, für viele jedoch noch steinig.
In einer Reihe anderer Branchen hat der Einsatz von KI/ML bereits exponentiell zugenommen. Ein O'Reilly-Bericht aus dem Jahr 2021 zeigt, dass IT und Elektronik an der Spitze der Rangliste stehen (17 %), gefolgt von Finanzdienstleistungen (15 %), Gesundheitswesen (9 %) und Bildung (8 %).
Die Tatsache, dass KI/ML in der Marktforschung noch eine relativ kleine Rolle spielen, schmälert jedoch keineswegs die Erwartungen der Branche:
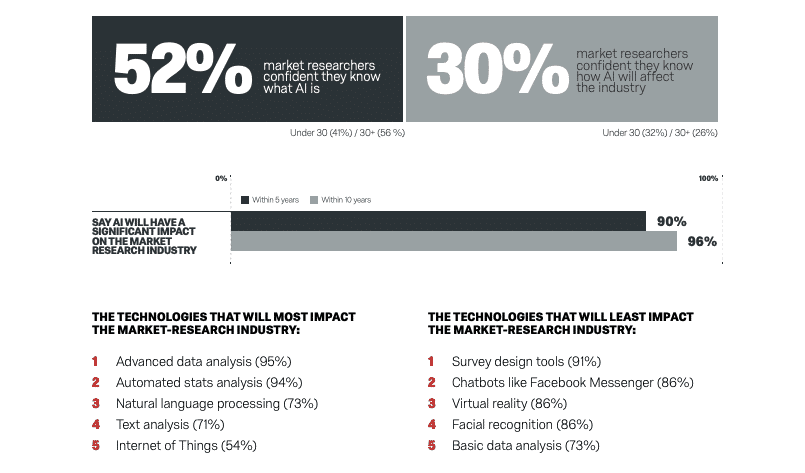
Laut einer
von Qualtrics durchgeführten Umfrage
In diesem Jahr ist gut die Hälfte der befragten Marktforschungsentscheider davon überzeugt, dass sie genau wissen, was KI ist; fast alle gehen davon aus, dass KI/ML in den nächsten zehn Jahren einen erheblichen Einfluss auf die Entwicklung der Marktforschung haben wird; und rund 30 Prozent sind zuversichtlich, dass sie die Auswirkungen angemessen antizipieren können. Auch die Trendforscher der auf Experience Management spezialisierten SAP-Tochter prognostizieren, dass in spätestens fünf Jahren mindestens 25 Prozent aller Umfragen mit digitalen Assistenten durchgeführt werden.
Sie wollen Tucan.ai für Ihr Unternehmen testen?
Buchen Sie einen kostenlosen Beratungstermin!
Vorteile für die Markt- und CX-Forschung
KI/ML-Tools helfen Unternehmen, das Verhalten ihrer Kunden besser zu verstehen, welche Probleme sie haben und wie sie auf bestimmte Angebote reagieren. Sie ermöglichen es, Daten schneller und genauer zu erfassen, zu analysieren und zu interpretieren.
Spätestens seit der Veröffentlichung des von OpenAI entwickelten Sprachmodells ChatGPT vor einigen Wochen sind insbesondere computerlinguistische Methoden für Natural Language Processing in aller Munde. Mit NLP können Text- und Sprachdaten systematisch gesammelt und analysiert werden, um beispielsweise herauszufinden, wie sich Kunden verhalten und auf Reize reagieren. Komplexe Datenmuster können dann dank Algorithmen immer besser erkannt und interpretiert werden.
Lange Rede, kurzer Sinn: KI/ML bietet zahlreiche Möglichkeiten zur Optimierung von Erhebungs- und Analyseprozessen. Trotz der Herausforderungen bei der Entwicklung flexibler Modelle, die mit unvorhersehbarer Sprache arbeiten können, ist der Nutzen des Einsatzes von KI in der Markt- und CX-Forschung unübertroffen. Im Folgenden finden Sie einen Überblick über die wichtigsten Vorteile:
1. Einsparung von Ressourcen
Der größte Mehrwert von KI/ML liegt wohl in der Zeitersparnis, die dadurch erzielt wird. Eine wirksame Automatisierung kann die Dauer eines Projekts von Monaten auf Wochen oder sogar Tage verkürzen. Infolgedessen können Analysten und Marketingexperten mehr Zeit mit der Auswertung, Interpretation und dem Erzählen der Geschichte hinter den Daten verbringen als mit der Berechnung verallgemeinerbarer Zahlen oder dem Versuch, relevante Formulierungen zu verstehen. KI/ML ermöglicht es den Unternehmen auch, Personalressourcen anderweitig einzusetzen und die Kosten für externe Dienstleister zu senken.
2. Höhere Datenqualität
Es gibt viele Herausforderungen, denen sich Unternehmen und Marken heute stellen müssen, wenn es um den effizienten Zugang, die Nutzung und Verwertung von Daten geht. Laut dem aktuellen Dell Digital Transformation Index (2020) sind Datenüberlastung und die "Unfähigkeit, Erkenntnisse aus Daten zu gewinnen" die größten Hindernisse für eine erfolgreiche digitale Transformation.
Eine weitere große Herausforderung im Bereich der Datenanalyse sind sogenannte Datensilos. Damit sind Datenbestände gemeint, auf die wenig oder gar nicht zugegriffen werden kann, z.B. weil sie schlecht aufbereitet oder in einzelnen Abteilungen isoliert wurden.
Obwohl KI/ML kein Wundermittel gegen solche Silos sind, bieten sie den Unternehmen Werkzeuge, um tiefere Einblicke zu gewinnen. Qualitativ hochwertigere Daten führen in der Regel zu wesentlich besseren Ergebnissen. Da KI-/ML-Tools die Analyse qualitativer Daten durch die Automatisierung von Erfassungs-, Verarbeitungs- und Verknüpfungsprozessen im Allgemeinen erleichtern, können wir jetzt viel mehr davon sammeln.
Darüber hinaus sind KI-Systeme heute in der Lage, Themen, Zusammenhänge und subtile Nuancen in und zwischen einzelnen Aussagen zu erkennen, die in der manuellen Dokumentation oft übersehen und übergangen werden. Die gewonnenen Freitextdaten ermöglichen zusätzliche, meist tiefere Einblicke.

Anwendungsfälle in der CX-Forschung
Im Folgenden möchte ich die häufigsten Anwendungsfälle von KI/ML in der Kundenerlebnisanalyse und einige innovative Unternehmen vorstellen, die den Weg weisen. Zu den am weitesten verbreiteten Methoden und Werkzeugen gehören Clustering- und Kategorisierungsalgorithmen, Text- und Stimmungsanalysen sowie Vorhersagemodelle.
Ein absolutes Muss für jeden Markt- und CX-Forscher ist definitiv Kantar Marketplace, das Mitte 2019 eingeführt wird. Die automatisierte Plattform, die in 70 Ländern verfügbar ist, liefert in kürzester Zeit entscheidungsrelevante Erkenntnisse, egal ob Unternehmen Feedback zu einer Idee benötigen, ein neues Produkt entwickeln oder eine Kampagne starten. Mit Marketplace bietet Kantar eine innovative Toolbox, die es Forschern, Fachleuten und Agenturen ermöglicht, durch Automatisierung tiefere Einblicke zu gewinnen und datengesteuerte Entscheidungen schneller zu treffen.
1. Automatische Sammlung
Ein vielversprechender Weg, CX-Verbesserung, Reibungsreduzierung und Kostensenkung Hand in Hand gehen zu lassen, ist die Automatisierung durch sogenannte Bots. Im neuen Jahr sind sie wohl der stärkste und sichtbarste Trend in Richtung KI/ML in der Markt- und Kundenforschung.
Als Reaktion auf die Corona-Pandemie ist die Nachfrage nach KI-Assistenten in der Industrie sprunghaft angestiegen. KI/ML-basierte Assistenz-Tools wie die von IBM, Zaoin und boost.ai helfen CX-Experten bei der Automatisierung und Optimierung von Analyseprozessen und Kundenbeziehungen. Virtuelle Agenten treffen beispielsweise eine Vorauswahl von Kundenanfragen und beantworten automatisch Routineanfragen. Mithilfe von skriptgesteuerten Regeln, KI und ML generieren sie automatisierte Antworten, lernen durch die Integration mit Backend-Systemen kontinuierlich neue Antworten auf grundlegende Fragen und können ein viel größeres Volumen an Anfragen als Menschen bearbeiten.
2. Clustering-Algorithmen
Apropos Big Data: Die meisten Unternehmen erfassen bereits eine Vielzahl von Kundeninteraktionen in ihren CRM-Systemen. Viele dieser Daten müssen jedoch erst richtig strukturiert werden, bevor sie tatsächlich Erkenntnisse liefern können. Anhand von Informationen über Kundeninteraktionen werden KI-Systeme nun darauf trainiert, die Arbeit eines Kundendienstmitarbeiters zu replizieren. Führende Anbieter wie Qualtrics verwenden hierfür Clustering-Algorithmen.
Clustering ist eine Technik, mit der Tausende von Zeilen unstrukturierter Konversationen automatisch klassifiziert werden können. Auf diese Weise können die Kundendienstdaten eines Unternehmens in Sekundenschnelle zur Analyse abgerufen und erfolgreiche Antworten, Häufigkeiten, Dringlichkeiten usw. angezeigt werden. Deep-Learning-Algorithmen werden eingesetzt, um Daten automatisch zu clustern, häufig gestellte Kundenfragen zu ermitteln und zu bewerten, inwieweit der Support automatisiert werden kann.
3. Automatische Verdichtung
KI ist auch für die Zusammenfassung von Videos und Audios in der CX-Forschung sehr nützlich. Durch den gezielten Einsatz von NLP können wir heute riesige Mengen an Video- und Audio-Feedback automatisch transkribieren und zusammenfassen. Wichtige Informationen werden so schneller erfasst und die Ressourcen können auf wichtigere Aufgaben konzentriert werden.
Das deutsche Softwareunternehmen Tucan.ai beispielsweise bietet neben der automatischen Aufnahme, Transkription und Codierung auch KI-generierte Gesprächszusammenfassungen an. Dies ist besonders nützlich für diejenigen, die große Datenmengen aus Interviews, Gruppengesprächen usw. analysieren und Zeit sparen wollen, weil sie diese nicht manuell dokumentieren oder kategorisieren müssen.
4. Kategorisierung und Kodierung
Die größte Herausforderung bei der Analyse von Anrufdaten ist in der Regel der Zeit- und Kostenaufwand, der mit der manuellen Kodierung und Kategorisierung der erfassten Daten verbunden ist. Auch hier kann die NLP-basierte SaaS-Plattform von Tucan.ai schnell Abhilfe schaffen. Daher wird es hierzulande bereits von namhaften Branchenakteuren wie Kantar und GIM eingesetzt.
Das Berliner Deep-Tech-Start-up hat ein eigenes KI-System entwickelt, das unter anderem Konversationsdaten automatisch codieren und kategorisieren kann. Große Datenmengen werden so schneller und präziser verarbeitet, was gezielte und umfassende Analysen ermöglicht und tiefere Einblicke in Ansichten und Kundenbedürfnisse erlaubt. Dies wiederum ermöglicht es, wichtige Ressourcen neu zuzuweisen, auf wiederkehrende Probleme schneller zu reagieren und Produkte und Dienstleistungen entsprechend anzupassen.
5. Prädiktive Modelle
Link AI ist eine KI-Plattform, die die Leistung einer digitalen Anzeige auf dem Markt vorhersagt. Es wurde mit Link trainiert, der weltweit größten Werbedatenbank, die über 230.000 umfragebasierte Tests mit 30 Millionen echten menschlichen Interaktionen enthält. Link AI zerlegt jede Anzeige in einzelne Bilder und zerlegt den Inhalt weiter in Bilder, Audio, Sprache, Objekte, Farben, Text und andere Attribute. Mit Hilfe von KI-Videoprozessoren extrahiert die Maschine dann bis zu 20.000 Merkmale aus der Videodatei, speist sie in maschinelle Lernmodelle ein und prognostiziert schließlich die Bewertung der Anzeige auf der Grundlage von Metriken für die "kreative Wirksamkeit".
KI-gestützte prädiktive Ansätze werden auch bei Umfragen immer beliebter. SurveyMonkey beispielsweise nutzt KI-gestützte Tools, um Unternehmen bei der Gestaltung und Analyse von Umfragen, der Vorhersage von Ausfüllraten und der Automatisierung der Datenanalyse zu unterstützen. Das Tool wird häufig für Kunden- und Mitarbeiterbefragungen, Marktforschung und andere Formen der Feedbackerfassung eingesetzt.
6. Audience Journey Tracking
Ein weiterer Bereich, in dem das computergestützte Lernen derzeit auf dem Vormarsch ist, ist das Audience Journey Mapping. Mit Hilfe von KI ist es nun möglich, eine Vielzahl von Kundeninteraktionen mit einer Marke oder einem Unternehmen von Anfang bis Ende genau zu dokumentieren. Auf diese Weise können Sie genauer feststellen, wann Kunden Reibungsverluste erfahren oder wo genau sie vom Interaktionsprozess abweichen.
Bekannte Beispiele für KI-gestütztes Audience Journey Mapping sind die Web-Tools HotJar, Appier und Fullstory. Sie können zum Beispiel genutzt werden, um gezielt einzelne Webseitensitzungen von Kunden zu beobachten, die einen Kauf nicht abschließen. Auf diese Weise lassen sich qualitative Erkenntnisse gewinnen, die bei statistischen Auswertungen großer Datensätze oft nicht richtig erfasst werden.
Für die Verfolgung der Publikumsströme wird die intelligente Software Knotch immer beliebter. Es kann verschiedene Interaktionen, die Kunden mit Unternehmen im Laufe der Zeit haben, zusammenführen und die Wege aufzeigen, die die meisten Konversionen bringen. Anstatt isolierte Kampagnen zu analysieren, die miteinander um Umsatzanteile konkurrieren, bestimmt Knotch genau, wie viel Einfluss jede digitale Interaktion oder jeder Inhalt auf den Umsatz hatte.
7. Automatische Stimmungsanalyse
Die Stimmungsanalyse nutzt KI und ML, um die in Worten ausgedrückten Emotionen zu ermitteln. Es folgt einer vorgegebenen Metrik, um zu verstehen, wie positiv, neutral oder negativ eine Aussage oder ein Text klingt. KI-Systeme können Millionen von Kommentaren in sozialen Medien, Bewertungsportalen und Online-Umfragen "voranalysieren".
Die innovative Nutzung der Stimmungsanalyse außerhalb der kommerziellen Markt- und Kundenanalyse wurde durch die KI-gestützte Social-Media-Analyse von En Marche im Zuge der Senatswahlen 2020 in Frankreich demonstriert: Die Partei von Emmanuel Macron nutzte Berichten zufolge NLP und Stimmungsanalyse, um tiefe Einblicke in die online geäußerten Präferenzen der Wähler zu bestimmten Themen zu gewinnen.
In der CX-Forschung ist sie vor allem für die Erreichung der folgenden Ziele nützlich:
-
Verbesserung der Marketingkampagnen: Beobachtung der Stimmungen, Verständnis der emotionalen Reaktionen auf bestimmte Botschaften und bessere Einschätzung der Rezeption der Wettbewerber.
-
Priorisierung im Kundenservice: schnellere Priorisierung von Tickets, Optimierung von Warteschlangen durch Automatisierung, schnellere und gezieltere Antworten auf Feedback
-
Detailliertes Verständnis der Kundenwahrnehmung von Produkten und Marken
-
Trendanalyse, Vorhersage: z. B. Reaktionen auf neue Schnittstellen oder Funktionen
-
Abwanderungsvorhersage: z. B. Erfassung negativer Stimmungen online in Echtzeit
Die Analyse von Gefühlen, im Englischen oft Opinion Mining genannt, ist ein Teilbereich des NLP. Im Kern erfasst und kategorisiert es automatisch eine große Anzahl individuell geäußerter Meinungen und verwandelt unstrukturierte Daten in verwertbare Informationen. Ein echter Spezialist für automatisierte Sentiment- und Emotionsanalysen, auf den unter anderem Qualtrics Marketplace setzt, ist zum Beispiel das britische Start-up Adoreboard mit seiner "Emotion AI Platform".
Vom Wettbewerbsvorteil zur Notwendigkeit
Bitte beachten Sie, dass dieser Artikel keinen Anspruch auf Vollständigkeit erhebt und lediglich einen ersten Überblick über die unzähligen neuen Akteure, Tools und Möglichkeiten geben soll, die dank der rasanten Fortschritte im Bereich KI/ML in letzter Zeit im CX-Segment aufgetaucht sind. Es gibt zahlreiche andere großartige Anwendungen, die ebenfalls Ihre Aufmerksamkeit verdienen. Wenn Sie etwas wissen, auf das Sie uns aufmerksam machen möchten, würden wir uns natürlich freuen, von Ihnen zu hören.
Dennoch zeigt dieser Artikel sehr deutlich, dass der gezielte Einsatz von KI/ML-Tools nicht mehr nur ein vielversprechender Wettbewerbsvorteil ist, sondern zu einer Grundvoraussetzung geworden ist, um im Wettbewerb um Aufmerksamkeit und Loyalität zu bestehen. Durch die zunehmende Digitalisierung unserer Gesellschaft und den immer stärker werdenden Wettbewerb im Online-Bereich ist es sehr viel schwieriger geworden, sich deutlich von den Mitbewerbern abzuheben.
Wer in der Lage ist, große Datenmengen zu verarbeiten, Metadaten zu analysieren und in kurzer Zeit Muster zu erkennen, gewinnt tiefere Einblicke in das Denken und Verhalten der Kunden. Unternehmen, die noch nicht über diese Fähigkeit verfügen, sollten so bald wie möglich mit der Erprobung innovativer Lösungen beginnen. Andernfalls werden sie in den kommenden Jahren unweigerlich ins Hintertreffen geraten.
Sie wollen Tucan.ai für Ihr Unternehmen testen?
Buchen Sie einen kostenlosen Beratungstermin!